Welcome to pan’s blog.
- Hi, this is Zhang Pan. I’m documenting my learning notes in this blog.
- Email: payne4handsome@163.com.
Welcome to pan’s blog.
preliminary 特征值与特征向量 设A为n阶实方阵,如果存在某个数$\lambda$及某个n维非零列向量$x$,使得$Ax=\lambda x$,则称$\lambda$是方阵A的一个特征值,$x$是方阵A的属于特征值的一个特征向量。 特征值与特征向量求解 $$Ax = \lambda x, x\not ={0} \\ \iff (A- \lambda E)x=0, x\not ={0} \\ \iff |A-\lambda E|=0 $$ 其中$|A-\lambda E|$称为特征多项式。 注:n阶方阵一定存在n个特征根(可能存在复根和重根) 协方差矩阵 假设存在一个m大小数据集,每个样本的特征维度为n。那么这个数据集可以表示为$X_{n * m}$, 其中每一列表示一个样本,每一行表示随机变量x的m个观察值。n行表示有n个随机变量。我们用 $K=(x_1, x_2, …,x_n)$表示这个随机变量序列,则这个变量序列的协方差矩阵为: $$C=(c_{ij})_{n * n}=\left[\begin{matrix} cov(x_1, x_1) & cov(x_1, x_2) & … &cov(x_1, x_n)\\ cov(x_2, x_1) & cov(x_2, x_2) & … &cov(x_2, x_n)\\ .& .& …& .\\ .& .& …& .\\ cov(x_n, x_1) & cov(x_n, x_2) & … &cov(x_n, x_n)\\ \end{matrix}\right]$$...
mysql innodb中的四种事务隔离级别 本文以实验的形式展示mysql Innodb引擎的四种事务隔离级别的影响。 四种隔离级别 隔离级别 脏读(Dirty Read) 脏读(Dirty Read) 幻读(Phantom Read) 未提交读(Read uncommitted) 可能 可能 可能 已提交读(Read committed) 不可能 可能 可能 可重复读(Repeatable read) 不可能 不可能 可能 可串行化(Serializable ) 不可能 不可能 不可能 未提交读(Read Uncommitted):允许脏读,也就是可能读取到其他会话中未提交事务修改的数据 提交读(Read Committed):只能读取到已经提交的数据。Oracle等多数数据库默认都是该级别 (不重复读) 可重复读(Repeated Read):可重复读。在同一个事务内的查询都是事务开始时刻一致的,InnoDB默认级别。在SQL标准中,该隔离级别消除了不可重复读,但是还存在幻象读 串行读(Serializable):完全串行化的读,每次读都需要获得表级共享锁,读写相互都会阻塞 详细说明 以下表(test)解释各个隔离级别,只有两个字段,一个id,一个account 插入测试数据 关闭mysql自动提交和设置隔离级别 查看是否开启自动提交 show variables like 'autocommit'; 打开或关闭自动提交 set autocommit = 1;//打开 set autocommit = 0;//关闭 查看数据库隔离级别 select @@tx_isolation;//当前会话隔离级别 select @@global.tx_isolation;//系统隔离级别 设置数据库隔离级别(当前会话) SET session transaction isolation level read uncommitted; SET session transaction isolation level read committed; SET session transaction isolation level REPEATABLE READ; SET session transaction isolation level Serializable; 未提交读(Read uncommitted) 关闭自动提交、设置对应隔离级别,开启两个会话,下面不在赘述...
本文主要是学习yolov4论文的一些学习笔记,可能不会那么详细。所以在文章最后列出了一些参考文献,供大家参考 yolo系列发展历程 yolo系列 发表时间 作者 mAP FPS mark yolov1 2016 Joseph Redmon 63.4 (VOC 2007+2012) 45 (448*448) yolov2 2016 Joseph Redmon 21.6 (coco test-dev2015) 59(480*480) yolov3 2018 Joseph Redmon 33 (coco) 20(608608), 35(416416) yolov4 2020 Alexey Bochkovskiy、Chien-Yao Wang 43.5 (coco) 65(608*608) yolov5 2020 Glenn Jocher (Ultralytics CEO) 48.2 (coco) 没有实测数据 没有论文,学术界不认可;该模型有不同大小的模型 scaled-yolov4 2021 Chien-Yao Wang、 Alexey Bochkovskiy 47.8 (coco) 62(608*608) 该模型有不同大小的模型 插曲,与中心思想无关 我们看到yolov1到v4 是由不同作者完成的,因为yolo 原作者已经在2018年推出CV界了,在yolov3论文的最后作者是这么写的 他发现他的研究成果被应用于战争,还有一些隐私的问题,所以他决定推出了…… yolo系统v1-v3由原作者Joseph Redmon完成,v4由AB(Alexey Bochkovskiy)完成,AB是参与前几个系列yolo代码的开发的,并且yolov4是得到原作者的认可的,在作者的原网页上有引用。 代码实现...
一 Transformer overview 本文结合pytorch源码以尽可能简洁的方式把Transformer的工作流程讲解以及原理讲解清楚。全文分为三个部分 Transformer架构:这个模块的详细说明 pytorch中Transformer的api解读 实际运用:虽然Transformer的api使用大大简化了打码量,但是还有需要自已实现一些代码的 Transformer架构 Transformer结构如下: 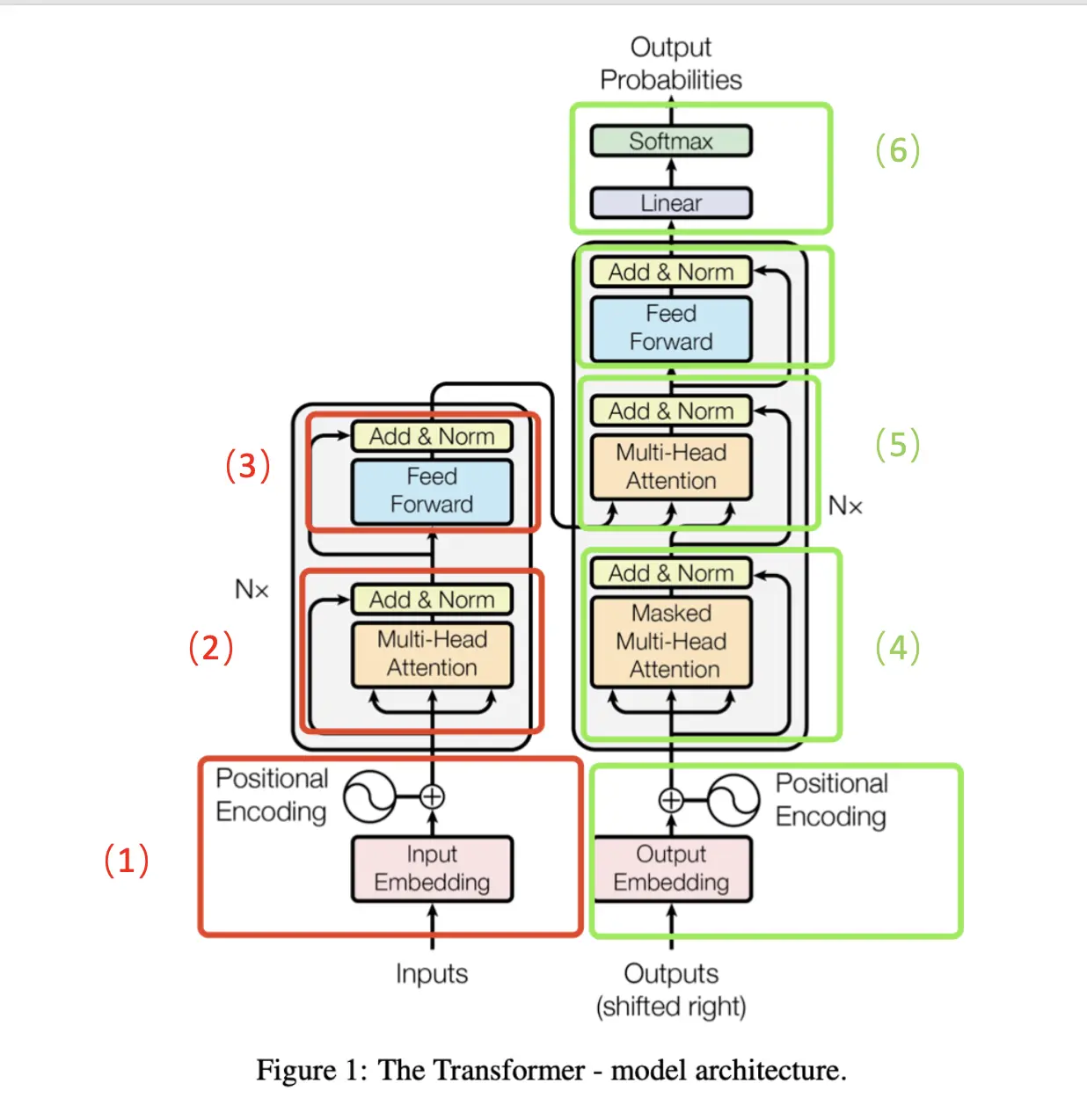 Transformer的经典应用场景就是机器翻译。 整体分为Encoder、Decoder两大部分,具体实现细分为六块。 输入编码、位置编码 Encoder、Decoder都需要将输入字符进行编码送入网络训练。 Input Embeding:将一个字符(或者汉字)进行编码,比如“我爱中国”四个汉字编码后会变成(4,d_model)的矩阵,Transformer中d_model等于512,那么输入就变成(4,512)的矩阵,为了方便叙述,后面都用(4,512)来当成模型的输入。 positional encoding:在Q、K、V的计算过程中,输入单词的位置信息会丢失掉。所以需要额外用一个位置编码来表示输入单词的顺序。编码公式如下 $PE_{pos,2i}=sin(pos/1000^{2i/d_{model}})$ $PE_{pos,2i+1}=cos(pos/1000^{2i/d_{model}})$ 其中,pos:表示第几个单词,2i,2i+1表示Input Embeding编码维度(512)的偶数位、奇数位。 论文中作者也试过将positional encoding变成可以学习的,但是发现效果差不多;而且使用硬位置编码就不用考虑在推断环节中句子的实际长度超过训练环节中使用的位置编码长度的问题;为什么使用sin、cos呢?可以有效的考虑句中单词的相对位置信息 多头注意力机制(Multi-Head Attention) 多头注意力机制是Transformer的核心,属于Self-Attention(自注意力)。注意只要是可以注意到自身特征的注意力机制就叫Self-Attention,并不是只有Transformer有。 示意图如下 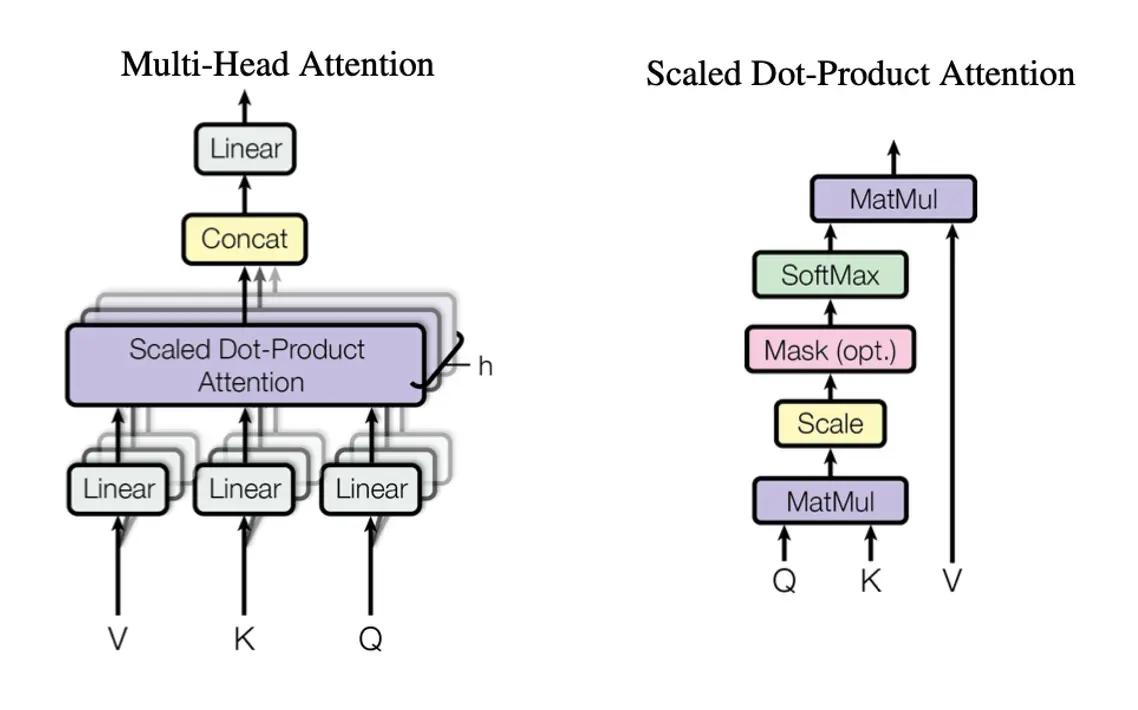 Multi-Head Attention的输入的Q、K、V就是输入的(4,512)维矩阵,Q=K=V。然后用全连接层对Q、K、V做一个变换,多头就是指的这里将输入映射到多个空间。公式描述如下: $MultiHead(Q,K,V)=Concat(head_1, head_2,…, head_n)W^o$ 其中 $head_i=Attention(QW^Q_i, KW^K_i, VW^V_i)$ 其中 $Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V$ 其中$W^Q_i\in R^{d_{model}*d_k}, W^K_i\in R^{d_{model}*d_k}, W^V_i\in R^{d_{model}d_v}, W^o\in R^{hd_vd_{model}}$, 论文中h=8, $d_k=d_v=d_{model}/h=512/8=64$ $QK^T$称为注意力矩阵(attention),表示两个句子中的任意两个单词的相关性。所以attention mask不一定是方阵。 前向传播模块 Q、K、V经过Multi-Head Attention模块再加上一个残差跳链,维度不变,输入维度是(4,512),输出维度还是(4,512),只不过输出的矩阵的每一行已经融合了其他行的信息(根据attention mask)。 这里前向传播模块是一个两层的全连接。公式如下: $FFN(x)=max(0, xW_1+b_1)W_2+b_2$, 其中输入输出维度为$d_model=512$, 中间维度$d_{ff}=2048$ 带Mask的多头注意力机制 这里的Mask Multi-head Attention与步骤2中的稍有不同。“我爱中国”的英文翻译为“I love china”。 在翻译到“love”的时候,其实我们是不知道“china”的这个单词的,所以在训练的时候,就需要来模拟这个过程。即用一个mask来遮住后面信息。这个mask在实际实现中是一个三角矩阵(主对角线及下方为0,上方为-inf), 定义为$attention_mask$大概就长下面这个样子 !...
机器学习基础之参数估计 一、参数估计 对所要研究的随机变量$\xi$,当它的概率分布的类型已知,但是参数未知,比如$\xi$服从正太分布$N(\alpha, \sigma)$。但是$\alpha, \sigma$这两个参数未知。那么这么确定这些未知参数呢?我们可以通过采样的方式,得到一批样本数据,用样本的统计量来估计总体的统计量。那么这种方式就是参数估计。 我们先来看一种简单的估计。 矩法估计:设总体$\xi$的分布函数$F(x; \theta_1,\theta_2, …, \theta_l)$中$l$个未知参数$\theta_1,\theta_2, …, \theta_l$。假定总体$\xi$的$l$阶原点绝对矩有限,并记$v_k=E(\xi^k) (k=1,2,…,l)$。现用样本的k阶原点矩来作为总体的k阶矩的估计量$\hat{v}_k$。即 $v_k=\hat{v}k=\frac{1}{n}\sum{i=1}^n\xi_i^k$ 那么通过样本的估计量,我们就可以估计出总体的一些参数。 比如假设$\xi$服从一个分布(不管什么分布),$E(\xi)=\alpha, D(\xi)=\sigma^2$。但其值未知,则由样本的一阶矩、二阶矩 $\hat{v}1=\frac{1}{n}\sum{i=1}^n\xi_i=\overline{\xi}$ $\hat{v}2=\frac{1}{n}\sum{i=1}^n\xi^2_i$ 总体的一阶矩、二阶矩 $v_1=E(\xi^1)=\alpha, v_2=E(\xi^2)=D(\xi)+(E(\xi))^2=\sigma^2+\alpha^2$ 令$v_1=\hat{v}_1, v_2=\hat{v}_2$, 就可以解出参数$\alpha, \sigma$的值. $\hat{\alpha}=\overline{\xi}\ \hat{\sigma^2}=\frac{1}{n}\sum_{i=1}^n\xi^2_i-(\overline{\xi}^2)=\frac{1}{n}\sum_{i=1}^n(\xi_i-\overline{\xi})^2=S^2$ 二、极大似然估计(Maximum Likelihood Estimate) 矩法估计要求随机变量$\xi$的原点矩存在。再者,样本矩的表达式用总体$\xi$的分布函数表达式无关,因此矩法估计没有充分利用分布函数对参数提供的信息。所以很多时候我们采用极大似然估计 (极大似然估计)设总体的$\xi$的密度函数为$f(x;\theta_1, \theta_2, …, \theta_l)$,其中$\theta_1, \theta_2, …, \theta_l$为未知参数。$\xi_1, \xi_2, …, \xi_n$为样本,它的联合密度函数为$f(x_1, x_2, …, x_n;\theta_1, \theta_2, …, \theta_l)$。 称 $L(\theta_1, \theta_2, …, \theta_l)=\prod_{i=1}^nf(x_i; \theta_1, \theta_2, …, \theta_l)$为$\theta_1, \theta_2, …, \theta_l$的似然函数。若有$\hat{\theta_1}, \hat{\theta_2}, …, \hat{\theta_l}$使得下试成立: $L(\hat{\theta_1}, \hat{\theta_2}, …, \hat{\theta_l})=max {L(\theta_1, \theta_2, …, \theta_l)}$, 则称$\hat{\theta_1}, \hat{\theta_2}, …, \hat{\theta_l}$为为参数$\theta_1, \theta_2, …, \theta_l$的极大似然估计量...