引言
最近在看相对位置编码的知识,本文算是对位置编码的总结吧。本文简单回顾绝对位置,然后介绍相对位置编码和PoRE(Rotary Position Embedding)
preliminary
绝对位置编码
由于Transformer(Attention Is All You Need)的attention机制本身是没有引入位置信息的,例如,Sequence 1: ABC, Sequence 2: CBA, 两个Sequence中单词A经过Transformer的encode后,编码是一样的。但是在真实世界中,句子中单词的顺序对应语义理解是非常重要的。所以Transformer在计算MHA之前会将输入序列的词嵌入(embedding)加上一个位置信息,由于这个位置信息是直接加在embedding上的,所以也被称为绝对位置编码。在Transformer中的绝对位置编码实现是Sinusoidal位置编码,在BERT和GPT位置编码则当成是可学习参数。
Sinusoidal位置编码
$$\begin{cases} p_{k,2i} = sin(k/10000^{2i/d})\\ p_{k,2i+1} = cos(k/10000^{2i/d}) \end{cases}$$
$p_{k,2i}, p_{k,2i+1}$是位置k的位置编码向量的第$2i,2i+1$个分量,d是位置编码向量的维度(与输入embedding的维度相同)。
绝对位置编码的Attention
对于输入序列的$X = (x_1, x_2, …,x_i,…,x_j, …, x_n)$, 经过attention计算后的输出为$Z=(z_1, z_2, …,z_i,…,z_j,…,z_n)$, 其中$x_i \in R^d, z_i \in R^d$。 attention计算如下:
$$\begin{cases} q_i = (x_i+pi)W_Q \\ k_j = (x_j+pj)W_K \\ v_j = (x_j+pj)W_V \\ a_{i,j} = softmax(\frac{q_ik_j^T}{\sqrt d }) \\ z_i = \sum_j a_{i,j}v_j \end{cases} $$
复数基础
在RoPE的一些证明中会用到复数的一些知识(当然不用复数也是可以的,只不是证明看起来麻烦点),所以在这里稍作回顾。
复数
若$z = a+bi$,则z的共轭复数$\bar{z} = a-bi$, 其中$\bar{z}$也可记为$z^*$。
在二维平面,复数$z = (a,b)$, 其中$a$为实轴分量,$b$为虚轴分量。
欧拉公式
$$e^{ix} = cos(x)+i\ sin(x)$$ 其中i为虚数单位
复数的一些性质
$(z_{1}z_{2})^\ast = z^\ast_{1} \ast z^\ast_{2}$
$(e^{ix})^* = e^{-ix}$
证明如下: $$ \begin{align} (e^{ix})^* &= (cos(x)+i\ sin(x))^* \\ &=cos(x)-i\ sin(x) \\ &=cos(-x) +i\ sin(-x) \\ &= e^{-ix} \end{align} $$
$e^{ix}*(e^{iy})^* = e^{i(x-y)}$
$<z_1, z_2> = Re[z_1z_2^*]$
两个二维向量的内积,等于把它们当复数看时,一个复数与另一个复数的共轭的乘积实部,其中Re是复数的实部的意思,这个证明也比较简单,这里不再赘述。
相对位置编码
首先,为什么需要相对位置编码?那肯定是为了解决绝对位置编码的一些问题的,一般认为绝对位置编码的缺点是缺乏外推性。对于绝对位置编码由于在训练的时候位置编码表的长度已经固定了,所以在推理的时候无法推理更长的输入;对于Sinusoidal位置编码,是可以支持无限输入长度的,对于其外推性的探讨参见再论大模型位置编码及其外推性(万字长文),这里不再赘述。
相对位置编码提出
相对位置编码起源于google的论文《Self-Attention with Relative Position Representations》,后来很多的相对位置编码都是以此为基础修改。
在绝对位置编码的基础上改动如下:
去掉绝对位置编码$pi,pj$
$$\begin{cases} q_i = (x_i)W_Q \\ k_j = (x_j)W_K \\ v_j = (x_j)W_V \\ a_{i,j} =softmax(\frac{q_ik_j^T}{\sqrt d }) \\ z_i = \sum_j a_{i,j}v_j \end{cases} $$
对$a_{i,j}, z_i$改动如下:
$$ a_{i,j}=softmax(\frac{x_iW_Q(x_jW_K+a_{ij}^K)^T}{\sqrt d })\\ z_i = \sum_j a_{i,j}(v_j+a_{ij}^V) = \sum_j a_{i,j}(x_jW_V+a_{ij}^V) $$ 其中$a_{ij}^K, a_{ij}^V$就是新加的相对位置编码,可以是可学习的,也可以三角的。 由于表示的相对位置关系,所以对于距离$p=|i-j|$超过一定距离需要截断。 $$ a_{ij}^K = p_k[clip(i-j,p_{min},p_{max})]\\ a_{ij}^V = p_v[clip(i-j,p_{min},p_{max})] $$ 其中$p_k,p_v$可以是可学习的,也可以三角的。
注:后续很多相对位置编码的工作,相对位置编码都只加在注意力矩上,不加value上了,RoPE也是一样。
RoPE
旋转式位置编码(Rotary Position Embedding,RoPE),是苏剑林在2021年就构想出的位置编码,这是一种配合Attention机制能达到“绝对位置编码的方式实现相对位置编码”的设计。其来源以及详细的推导证明见参考文献让研究人员绞尽脑汁的Transformer位置编码和Transformer升级之路:2、博采众长的旋转式位置编码。
MHA的输入为输入序列经过tokenizer得到的token经过nn.Embedding后的词嵌入(word embedding),分别记为$q_m$,$k_n$,$v_n$。正如前文所言,苏剑林的出发点是通过绝对位置编码的方式实现相对位置编码。数学表达如下: $$<f(q, m),f(k,n)> = g(q, k, m-n)$$
如何理解这个公式呢?在q和k上进行$f$操作,该操作分别引入位置信息m和n(绝对位置编码),但是神奇的是引入的是绝对位置编码,但是经过向量的内积运算(任意两个位置的内积就是注意力矩阵)后就变成了相对位置编码。即$g$中的位置信息变成了m-n(相对位置编码)。
这里我们直接给出满足上述要求的$f$,至于苏神是如何想到的,还是要与参考苏神的博客和论文(ROFORMER: ENHANCED TRANSFORMER WITH ROTARYPOSITION EMBEDDING)。
$$f(q_m,m) = (W_qq_m)e^{im\theta}$$ $$f(q_k,n) = (W_kq_k)e^{in\theta}$$
其中,
- $W_q, W_k$是映射矩阵,$q_m, q_k$是词嵌入。对应的Transformer的MHA,如下图。
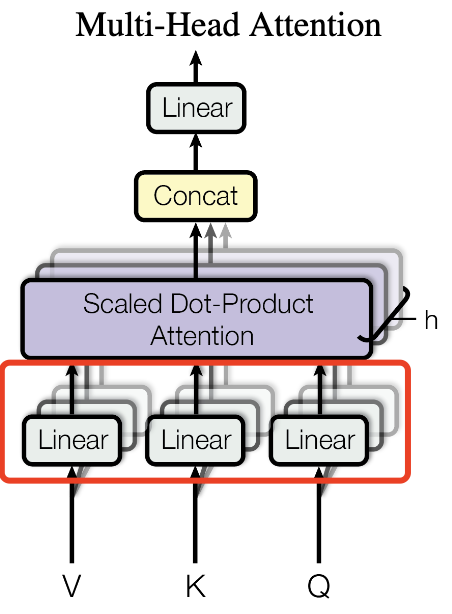
- $e^{im\theta}$就是f引入的操作。其中i是虚数单位。
那么下面我们重点理解一下这个操作,这么就无端端的引入一个复数了,而且还是这么复杂的复数。引入这个复数可以使得证明变得异常简洁,但是对于苏神而言,这些可能是很简单的操作。
由于复数只能定义在二维空间,所以这里我们先假设词嵌入$q_m, q_k$是二维的,实际中,词嵌入的维度都是512,768这种高维的。这里,我们先理解简单的,后面再扩充到高维空间。
$e^{im\theta}$通过欧拉公式展开就是$e^{im\theta} = cos(m\theta)+i\ sin(m\theta)$, 那么
$$ \begin{align} (a+bi)* e^{im\theta} &=(a+bi)* (cos(m\theta)+i\ sin(m\theta)) \\ &= a*cos(m\theta)-b*sin(m\theta) + i(a*sin(m\theta)+b*cos(m\theta))\\ &= \begin{bmatrix} cos(m\theta) & -sin(m\theta) \\ sin(m\theta) & cos(m\theta) \end{bmatrix} \begin{bmatrix}a\\ b\end{bmatrix} \end{align} $$
即不懂复数也没有关系,$f$操作对应了一个旋转矩阵 $$ \begin{bmatrix} cos(mx) & -sin(mx) \\ sin(mx) & cos(mx) \end{bmatrix} $$
那么下面我们证明下为什么引入$f$操作后,可以把绝对位置信息巧妙的利用attention的计算机制(向量内积)变成相对位置信息的。
证明一:利用复数
MHA的注意力矩阵就是$softmax(QK^T)$,简单起见,我们只计算任意两个向量的注意力。 记号如下:
- $q_m$: m位置的词嵌入(假设是2维度),向量表示为$(q_1, q_2)$
- $k_n$: n位置的词嵌入(假设是2维度),向量表示为$(k_1, k_2)$
- $W_q$: Q矩阵的映射矩阵,维度为2*2
- $W_k$: K矩阵的映射矩阵,维度为2*2
证明如下: $$ \begin{align} <f(q_m,m), f(q_n,n)> &= <W_qq_me^{im\theta}, W_kk_ne^{in\theta}> \\ &= Re[(W_qq_me^{im\theta})(W_kk_ne^{in\theta})^*] \\ &= Re[(W_qq_me^{im\theta})(e^{-in\theta}(W_kk_n)^*))] \\ &=Re[(W_qq_m)e^{i(m-n)\theta}(W_kk_n)^*)] \end{align} $$
证明二
$$ \begin{align} <f(q_m,m), f(q_n,n)> &= \left( \begin{bmatrix} cos(n\theta) & -sin(n\theta) \\ sin(n\theta) & cos(n\theta) \\ \end{bmatrix} \begin{bmatrix}k_1\\ k_2\end{bmatrix} \right)^T \begin{bmatrix} cos(m\theta) & -sin(m\theta) \\ sin(m\theta) & cos(m\theta) \\ \end{bmatrix} \begin{bmatrix}q_1\\ q_2\end{bmatrix}\\ &=[k_1, k_2]\left( \begin{bmatrix} cos(n\theta) & -sin(n\theta) \\ sin(n\theta) & cos(n\theta) \\ \end{bmatrix} \right)^T * \begin{bmatrix} cos(m\theta) & -sin(m\theta) \\ sin(m\theta) & cos(m\theta) \\ \end{bmatrix} \begin{bmatrix}q_1\\ q_2\end{bmatrix} \end{align} $$
记 $$M_n=\begin{bmatrix} cos(n\theta) & -sin(n\theta) \\ sin(n\theta) & cos(n\theta) \\ \end{bmatrix}$$ $$M_m=\begin{bmatrix} cos(m\theta) & -sin(m\theta) \\ sin(m\theta) & cos(m\theta) \\ \end{bmatrix}$$
下面只要证明 $M_n^TM_m$可以表示为$m-n$的形式就得证了
$$ \begin{align} M_n^TM_m &= \left(\begin{bmatrix} cos(n\theta) & -sin(n\theta) \\ sin(n\theta) & cos(n\theta) \\ \end{bmatrix}\right)^T\begin{bmatrix} cos(m\theta) & -sin(m\theta) \\ sin(m\theta) & cos(m\theta) \\ \end{bmatrix}\\ &=\begin{bmatrix} cos(n\theta) & sin(n\theta) \\ -sin(n\theta) & cos(n\theta) \\ \end{bmatrix}\begin{bmatrix} cos(m\theta) & -sin(m\theta) \\ sin(m\theta) & cos(m\theta) \\ \end{bmatrix} \\ &=\begin{bmatrix} cos(n\theta)cos(m\theta)+sin(n\theta)sin(m\theta) & -cos(n\theta)sin(m\theta)+sin(n\theta)*cos(m\theta) \\ -sin(n\theta)cos(m\theta)+cos(n\theta)*sin(m\theta) & sin(n\theta)sin(m\theta)+cos(n\theta)cos(m\theta) \end{bmatrix}\\ &=\begin{bmatrix} cos((m-n)\theta) & -sin((m-n)\theta)\\ sin((m-n)\theta) & cos((m-n)\theta) \end{bmatrix} \end{align} $$
注:最后一步用到了高中的三角函数的一些性质
当然还有一些更简洁的证明方法,但是都需要一些额外的数学基础,所以我们这里就不列举了,通过朴素的方法,我们证明了引入$f$操作后,可以把绝对位置信息巧妙的利用attention的计算机制(向量内积)变成相对位置信息
实际应用中PoRE
上面的证明我们都是假设word embedding的维度是2,但是实际应用中,word embedding都是高维的,比如512,768等。
所以我们只需要对高维的word embedding进行两两分组(word embedding的维度都是偶数)就可以了。所以一般形式的PoRE如下图中红色框中的矩阵。
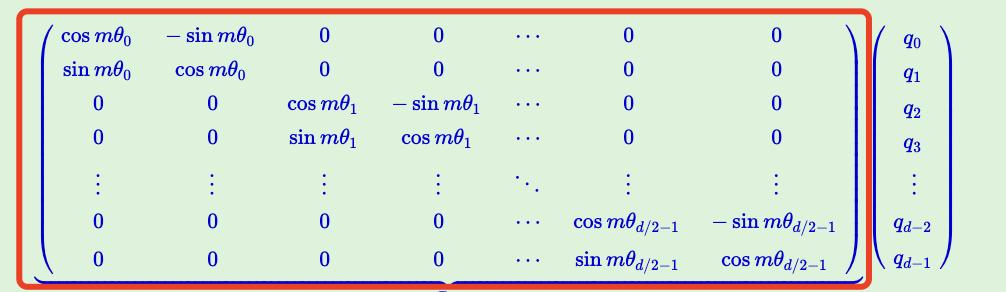
注
- 一般形式的PoRE中$\theta$是可以不同的
- 在RoFormer中$\theta$实现如下 $$\theta_i = 10000^{-2(i-1)/d}, i\in[1,2,…,d/2]$$
- 在实际代码实现中,每个位置如果都要初始化一个这么高维的矩阵,代价的高昂的,所以苏神连工程化都给你想好了。如下:
