机器学习基础二-反向传播
神经网络之所以可以训练,得益于与Hinton在1986年提出的反向传播算法。反向传播背后的数学原理就是链式法则。本文会具体的实例来演示反向传播具体的计算过程,让大家有一个实际的印象。文中公式都是一个字符一个字符敲出来的,转载请注明出处。文中参考了其他作者的一些例子和数据,均在参考文献中列出。
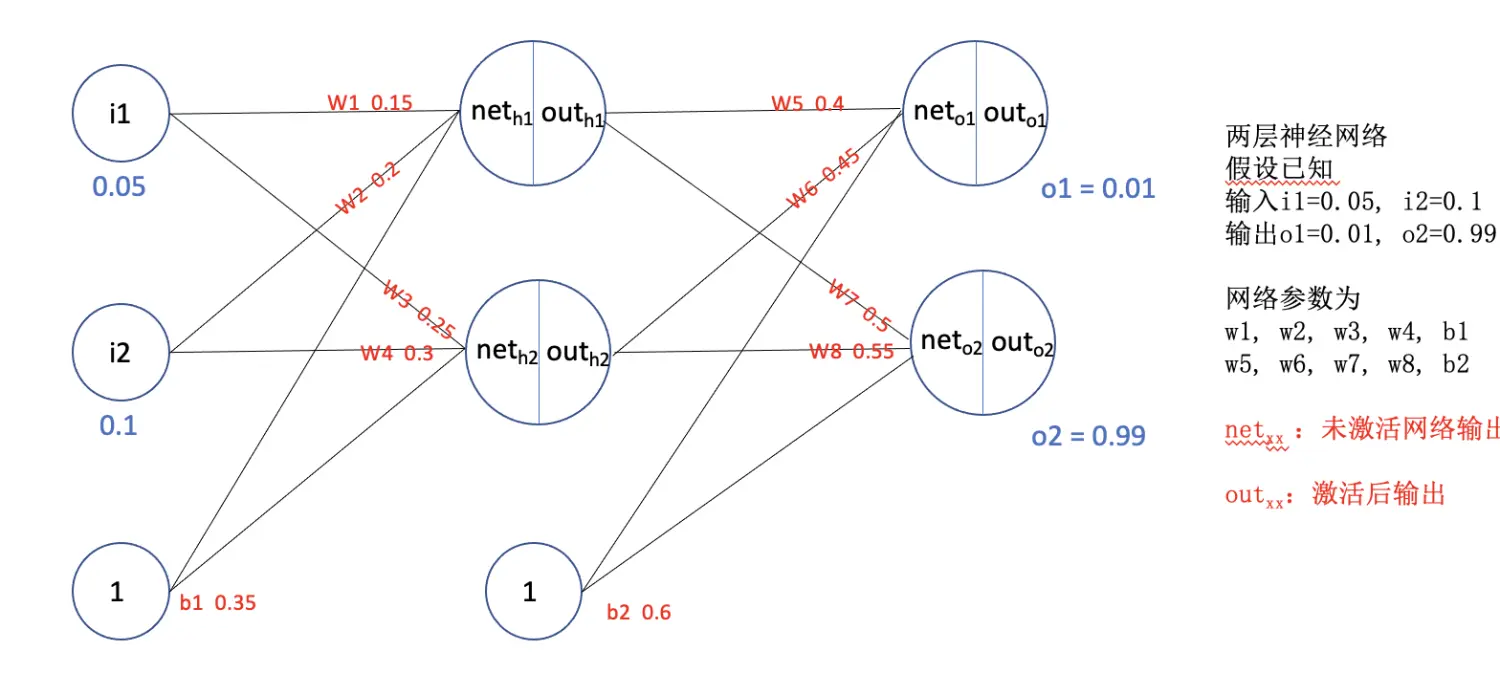 一个简单的两层神经网络如上图所示。其中
一个简单的两层神经网络如上图所示。其中
$i_1, i_2$ : 训练时候实际的输入
$o_1, o_2$ : 训练时候实际的输出(ground truth)
$out_{o1}, out_{o2}$: 模型预测的结果
我们的目的就是通过反向传播,更新模型的参数$w_i,b_i$, 使得$out_{o1}, out_{o2}$尽可能的逼近$o_1, o_2$。
本例中激活函数用$sigmod(x)=\frac{1}{1+e^{-x}}$;
损失函数用$L_2=\frac{1}{2} \times (target-output)^2$
前向传播
- 隐藏层计算
$net_{h1}=w_1 \times i_1+w_2 \times i_2+b_1=0.15 \times 0.05+0.2 \times 0.1+0.35=0.3775$
$out_{h1}=sigmod(net_{h1})=\frac{1}{1+e^{-0.3775}}=0.593269992$
同理 $out_{h2}=0.596884378$
- 输出层计算
$net_{o1}=w_5 \times out_{h1}+w_6m \times out_{h2}+b_2\=0.4 \times 0.593269992+0.45 \times 0.596884378=1.105905967$
$out_{o1}=sigmod(net_{o1})=0.75136507$
同理 $out_{o2}=0.772928465$
最终我们看到前向传播的结果为(0.75136507,0.772928465)与我们的目标(0.01,0.99)差的比较多,所以接下来用反向传播算法学习
反向传播
要想反向传播,还需要两步(1)计算损失,(2)计算梯度。过程如下图所示
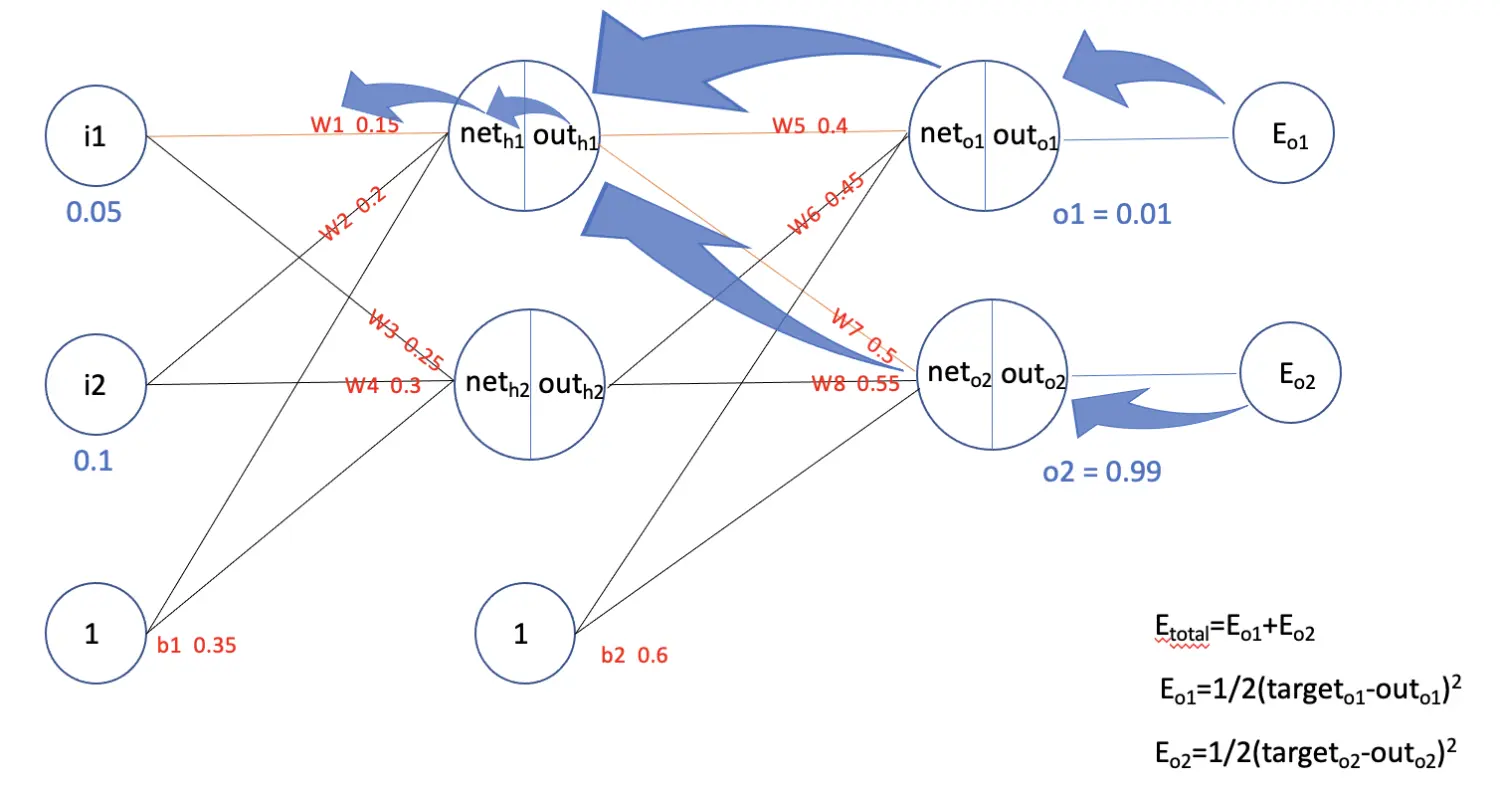
总的损失$E_{total}=E_{o1}+E_{o2}$,其中
$$\begin{align} E_{o1} &=\frac{1}{2}(target_{o1}-out_{o1})^2 \\ &= \frac{1}{2}(0.01-0.75136507)^2=0.274811083 \end{align}$$
$$E_{o2}=\frac{1}{2}(target_{o2}-out_{o2})^2=0.023560026$$
$$E_{total}=E_{o1}+E_{o2}=0.274811083+0.023560026=0.298371109 $$
- 计算参数$w_5$的梯度 根据链式法则,公式如下:
$\frac{\partial E_{total}}{\partial w_5}=\frac{\partial E_{total}}{\partial out_{o1}} \times \frac{\partial out_{o1}}{\partial net_{o1}} \times \frac{\partial net_{o1}}{\partial w_5}$
$\frac{\partial E_{total}}{\partial out_{o1}}=(target_{o1}-out_{o1}) \times -1=-(0.01-0.75136507)=0.74136507$
$\frac{\partial out_{o1}}{\partial net_{o1}}=out_{o1}*(1-out_{o1})=0.75136507(1-0.75136507)=0.186815602$
$\frac{\partial net_{o1}}{\partial out_{w_5}}=out_{h1}=0.593269992$
所以$\frac{\partial E_{total}}{\partial w_5}=0.741365070.1868156020.593269992=0.082167041$
在计算后面参数的梯度时,都会需要用到$\frac{\partial E_{total}}{\partial net_{o1}}, \frac{\partial E_{total}}{\partial net_{o2}}$的值。我们把这个称为输出层的误差, 符号记为:
$\delta_{o1}=\frac{\partial E_{total}}{\partial net_{o1}}=0.74136507*0.186815602=0.138498562$
$\delta_{o2}=\frac{\partial E_{total}}{\partial net_{o2}}=-0.038098236$
- 计算参数$w_1$的梯度 要计算$w_1$的梯度,就要计算$\frac{\partial E_{total}}{\partial out_{h1}}$, 如上图所示,有两条路线(图中蓝色箭头)会向$\frac{\partial E_{total}}{\partial out_{h1}}$传播梯度。
$\frac{\partial E_{total}}{\partial out_{h1}}=\frac{\partial E_{o1}}{\partial out_{h1}}+\frac{\partial E_{o2}}{\partial out_{h1}}$
$\frac{\partial E_{o1}}{\partial out_{h1}}=\frac{\partial E_{o1}}{\partial net_{o1}}*\frac{\partial net_{o1}}{\partial out_{h1}}$
$\frac{\partial E_{o2}}{\partial out_{h1}}=\frac{\partial E_{o2}}{\partial net_{o2}}*\frac{\partial net_{o2}}{\partial out_{h1}}$
上式中 $\frac{\partial E_{o1}}{\partial net_{o1}}, \frac{\partial E_{o2}}{\partial net_{o2}}$在计算$w_5$的梯度时已经计算好了。
$\frac{\partial net_{o1}}{\partial out_{h1}}=w_5=0.4\ \frac{\partial net_{o2}}{\partial out_{h1}}=w_7=0.5$
所以
$\frac{\partial E_{o1}}{\partial out_{h1}}=0.138498562*0.4=0.055399425$
$\frac{\partial E_{o2}}{\partial out_{h1}}=−0.038098236*0.5=-0.019049119$
$\frac{\partial E_{total}}{\partial out_{h1}}=\frac{\partial E_{o1}}{\partial out_{h1}}+\frac{\partial E_{o2}}{\partial out_{h1}}=0.055399425+(-0.019049119)=0.036350306$
最终
$\frac{\partial E_{total}}{\partial w_1}=\frac{\partial E_{total}}{\partial out_{h1}} \times \frac{\partial out_{h1}}{\partial net_{h1}} \times \frac{\partial net_{h1}}{\partial net_{w_1}}=0.036350306 \times out_{h1} \times (1-out_{h1}) \times i_1=0.036350306 \times \times0.593269992 \times (1-0.593269992) \times 0.05=0.000438568$
补充说明
- sigmod求导推导
$f(x) = \frac{1}{1+e^-x}$
$\dot{f(x)}=-\frac{1}{(1+e^-x)^2} \times e^{-x} \times -1=\frac{1}{(1+e^-x)} \times \frac{e^{-x}}{(1+e^-x)}=f(x) \times (1-f(x))$
- 分类任务,输出层损失
以上是以sigmod激活,MSE损失的反向传播(回归问题);如果已经softmax激活,交叉熵顺序的反向传播如何呢(分类问题)?
如何计算分类问题的输出层损失,符号定义如下
- $z_i$: 网络最后未经过激活的输出
- $p_i$: 经过激活后的输出(这里激活函数为softmax)
- $q_i$: one_hot编码后target的分量
- N: 类别的数量,等于length($q_i$)
已知: $p_i=\frac{e^{z_i}}{\sum_k^Ne^{z_k}}$
$\sum_i^Nq_i=1$
$loss=-\sum_i^Nq_ilog(p_i)$
下求:损失层输出
$\frac{\partial loss}{\partial z_i}=\frac{\partial loss}{\partial p_i}\frac{\partial p_i}{\partial z_i}+\sum_{j\not =i}^N\frac{\partial loss}{\partial p_j}\frac{\partial p_j}{\partial z_i}$
其中
$\frac{\partial loss}{\partial p_i}\frac{\partial p_i}{\partial z_i}=-\frac{q_i}{p_i}(p_i+\frac{e^{z_i}}{-({\sum_k^Ne^{z_k})^2}}e^{z_i})=-\frac{q_i}{p_i}(p_i+(-{p_i}^2))=-q_i(1-p_i)$
$\sum_{j\not =i}^N\frac{\partial loss}{\partial p_j}\frac{\partial p_j}{\partial z_i}=-\sum_{j\not =i}^N\frac{q_j}{p_j}\frac{e^{z_j}}{-(\sum_k^Ne^{z_k})^2}e^{z_i}=-\sum_{j\not =i}^N\frac{q_j}{p_j}(-p_jp_i)=\sum_{j\not =i}^Nq_jp_i$
所以
$\frac{\partial loss}{\partial z_i}=-q_i(1-p_i)+\sum_{j\not =i}^Nq_jp_i=-q_i+q_ip_i+p_i*\sum_{j\not =i}^Nq_j=-q_i+p_i*(q_i+\sum_{j\not =i}^Nq_j)=-q_i+p_i*1=p_i-q_i$
这是一个非常简洁的形式,可直接使用
以上以多层感知机网络为例,详细说明了反向传播的计算过程
全连接神经网络反向传播的一般形式
定义全连接神经网络
$z^l$: 神经网络第l层的输入, 初始化输入$z^0$
$a^l$:$z^l$激活后的输出
$W^l$: 神经网络第l层的参数
$b^l$: 神经网络第l层的参数的偏置项
那么神经网络前项传播的过程为:
$z^{l}=W^la^{l-1}+b^l$
$a^{l-1}=\sigma(z^{l-1})$, $\sigma$为激活函数
模型的损失函数定义为: $C=\frac{1}{2}||a^L-y||_2^2$。
反向传播需要计算 $\frac{\partial C}{\partial W^l}, \frac{\partial C}{\partial b^l}$ 。
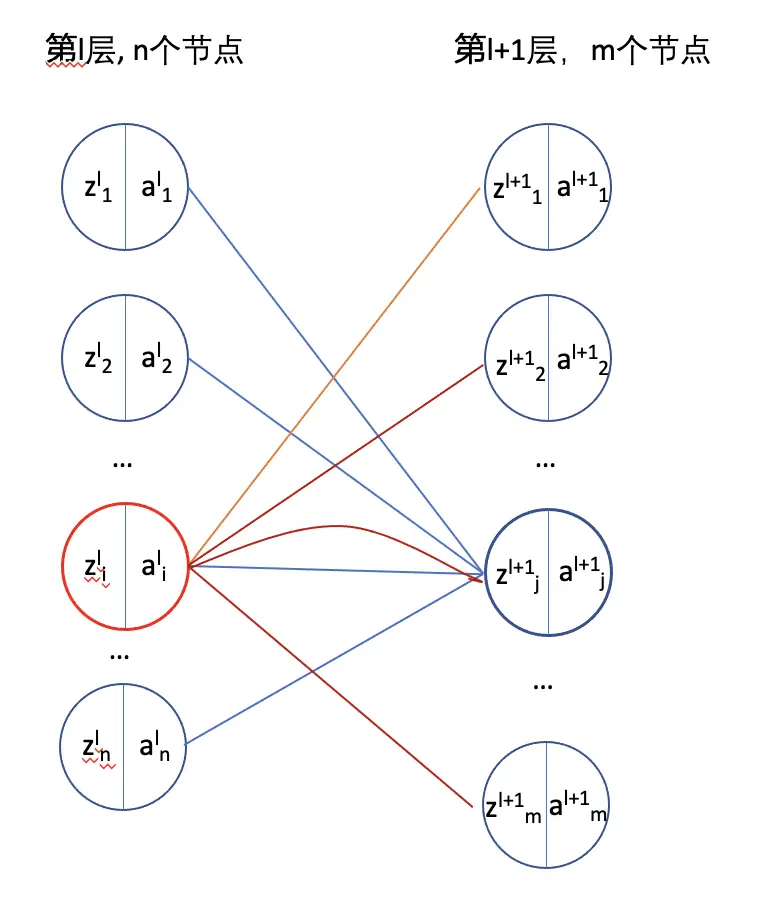
$\frac{\partial C}{\partial W^l}=\frac{\partial C}{\partial z^l}*\frac{\partial z^l}{\partial W^l}$
$\frac{\partial C}{\partial z^l}$ 定义为l层的误差,记$\delta^l$。
$\frac{\partial C}{\partial W^l}=\frac{\partial C}{\partial z^l}*\frac{\partial z^l}{\partial W^l}=\delta^l(a^{l-1})^T$
$\frac{\partial C}{\partial b^l}=\delta^l$
这里需要好好理解一下为什么$\frac{\partial z^l}{\partial W^l}$用$a^{l-1}的转置表示$,因为涉及到矩阵的运算,所以建议好好理解一下,可以借助于上图。那只要再计算$\delta^l$就可以了
$\delta^l=\frac{\partial C}{\partial z^l}=\frac{\partial C}{\partial z^{l+1}}\frac{\partial z^{l+1}}{\partial z^l}=\delta^{l+1}\frac{\partial z^{l+1}}{\partial z^l}$
$z^{l+1}=W^{l+1}a^{l}+b^{l+1}=W^{l+1}\sigma(z^l)+b^{l+1}$
$\delta^l=(W^{l+1})^T\delta^{l+1}*\dot{z^l}$
最后一层输出层的误差
$\delta^L=\frac{\partial C}{\partial z^L}=\frac{\partial C}{\partial a^L}\frac{\partial a^L}{\partial z^L}=(a^L-y)*\dot{\sigma(z^L)}$
那么通过计算L层,L-1,L-2等等这样的计算就可以计算每一层的参数的梯度。
卷积网络-反向传播
卷积网络的反向传播,参考文献4中讲解的非常好,大家直接看作者的原文即可。
循环神经网络网络-反向传播
参考文献