Updated on 2023-06-24: add AdamW
梯度下降是优化神经网络和机器机器学习算法的首选优化方法。本文重度参考SEBASTIAN RUDER的文章。对于英文比较好的同学请直接阅读原文。本文只为个人的学习总结,难免有所欠缺和不足。
一、梯度下降变种
根据训练数据集的大小,梯度下降有三种变体,但是本质是一样的,不一样的是每次使用多少条样本。如果内存一次可以计算所有样本的梯度,称为:批梯度下降(Batch gradient descent);如果内存一次只允许一个样本,称为:随机梯度下降(Stochastic gradient descent);大部分时候,内存一次是可以计算部分样本的,称为:最小批梯度下降(Mini-batch gradient descent)。三种变体的数据表达如下:
1.1批梯度下降(Vanilla gradient descent,又称Batch gradient descent)
$\theta = \theta - \eta \cdot \nabla_\theta J( \theta)$
1.2随机梯度下降(Stochastic gradient descent)
$\theta = \theta - \eta \cdot \nabla_\theta J( \theta; x^{(i)}; y^{(i)})$
1.3最小批梯度下降(Mini-batch gradient descent)
$\theta = \theta - \eta \cdot \nabla_\theta J( \theta; x^{(i:i+n)}; y^{(i:i+n)})$
注意,在其他地方并没对上述三种变体做严格区别,统称为SGD(随机梯度下降),下文其余部分,我们也不加区分,统称为SGD
二、梯度下降的几种优化方法
传统的梯度下降法不能保证一个很好的收敛,而且有一些挑战需要被解决。
- 选择这个合适的学习率是比较困难的。特别是对一个新的模型和新数据集时候,我们是不知道选择什么样的学习率是合适的。只能不断的去尝试。
- 学习率调度算法可以在训练的过程中去调整模型的学习率。模型一开始的时候可以使用大一点的学习率,后面再使用小一点的学习率去微调模型。更好的方法是一开始也用一个小的学习率去warm-up训练,让参数先适应数据集。但是无论哪种学习率调度算法都需要预先定义调度算法,这种方法也是没有办法很好的适应模型的特征的、
- 对每一个参数都使用同样的学习率是不合适的。对于稀疏的数据或者特征非常不均衡的数据。最好是使用不同学习率学习不同频率的特征。
- 另外的挑战是对于高阶非凸的损失函数,往往会陷于局部极值点。还有一种鞍点的情况,模型也是很难学习的。此时损失函数在各个方向的梯度接近于0。SGD是很难逃脱与鞍点或者局部极值点的。
针对上面的一些问题,慢慢出现了一些针对梯度下降的优化方法。 在介绍SGD变种之前。先给出各个变种的一般范式。后天的各个变种优化方法都离不开这个范式。
(1)计算目标函数关于参数的梯度
$g_t = \nabla_\theta J( \theta)$
(2)根据历史梯度计算一阶和二阶动量(二阶指的是梯度的平方)
$$m_t = \phi(g_1, g_2, …, g_t)$$ $$v_t = \psi(g_1, g_2, …, g_t)$$
(3)更新模型参数 $\theta_{t+1}=\theta_t-\frac{1}{\sqrt{v_t+\epsilon}}m_t$
2.1 动量法(Momentum)
$$v_t = \gamma v_{t-1} + \eta \nabla_\theta J( \theta) $$ $$ \theta = \theta - v_t $$
做一个简单的推导。
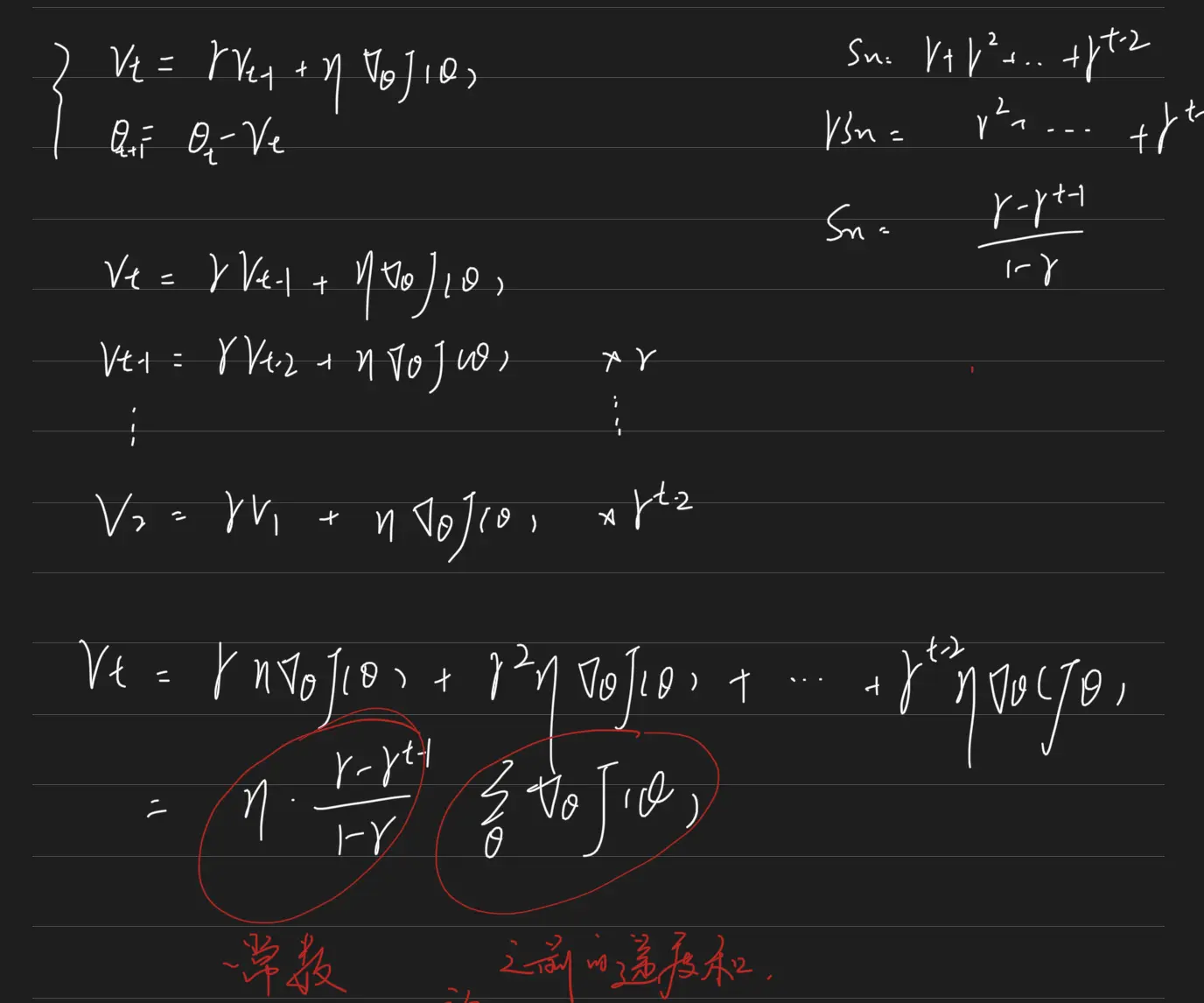 发现,参数$\theta$每次的更新量为之前的梯度和乘以一个常量。下图坐标是朴树SGD的图示,右边是加上动量的SGD图示。发现在水平方向得到了加速,在竖直方向得到了收敛。所以如果之前1到t-1时刻的梯度方向比较一致,那么加了动量的SGD会在这个方向加速;如果之前时刻的梯度方向不太一致,或者说抖动的比较厉害;那么加了动量的SGD会在这个方向减速,也就是以更小的速度更新参数。
发现,参数$\theta$每次的更新量为之前的梯度和乘以一个常量。下图坐标是朴树SGD的图示,右边是加上动量的SGD图示。发现在水平方向得到了加速,在竖直方向得到了收敛。所以如果之前1到t-1时刻的梯度方向比较一致,那么加了动量的SGD会在这个方向加速;如果之前时刻的梯度方向不太一致,或者说抖动的比较厉害;那么加了动量的SGD会在这个方向减速,也就是以更小的速度更新参数。

Adagrad
SGD、SGD-M都是相同的学习率更新参数。但是对于高频出现的特征我们希望用更小的学习率更新参数。所以提出了自适应梯度更新方法Adagrad。Adagrad对于低频出现的特征我们希望用更大的学习率更新参数。所以在稀疏数据的场景下Adagrad表现较好。Adagrad中的ada是adapt(自适应)的意思
$$ \theta_{t+1, i} = \theta_{t, i} - \dfrac{\eta}{\sqrt{G_{t, ii} + \epsilon}} \cdot g_{t, i} $$
其中$G_{t,ii}$表示$\theta$过去所有时刻梯度平方和,注意分母是带根号的,不带根号效果会很差。 缺点:分母会越来越大,导致最后的学习率是无穷小的值。这样模型就学不到东西了。
RMSprop
$$ E[g^2]_{t} = 0.9E[g^2]_{t-1}+ 0.1g^2_t$$
$$ \theta_{t+1} = \theta_{t} - \dfrac{\eta}{\sqrt{E[g^2]_t} + \epsilon} g_t$$
从表达是可以看出RMSprop是为了解决Adagrad中学习率会越来越小的问题。RMSprop处理使用之前的累计额梯度平方和还使用了当前时刻的梯度平方。这样就会防止学习率越来越小。
Adam
Adam可以认为是RMSprop和Momentum的结合。
$$m_t = \beta_1 m_{t-1} + (1 - \beta_1) g_t$$ $$ v_t = \beta_2 v_{t-1} + (1 - \beta_2) g_t^2 $$
其中$m_0=0, v_0=0$ 由于$\beta_1, \beta_2$都是趋向于1的数,所以开始时刻$m_t,v_t$趋向于0的一端,导致一开始的时候梯度很小。所以作者Adam对上面的公式做了偏差矫正(bias-corrected)。公式如下
$$\hat{m}_t = \dfrac{m_t}{1 - \beta^t_1}$$ $$\hat{v}_t = \dfrac{v_t}{1 - \beta^t_2}$$
即在原来的基础上除以$1-\beta^t$。 那么$\hat{m}_0=g_1$, 随着t的变大,$1-\beta^t$趋向于1。即$\hat{m}_t$趋向于$m_t$。 最终参数更新表达如下:
$$ \theta_{t+1} = \theta_{t} - \dfrac{\eta}{\sqrt{\hat{v}_t} + \epsilon} \hat{m}_t $$
所以理论上Adam优化方法是比较好的优化方法。即加了动量,针对不同参数又使用了不同的学习率。当时在目前很多开源的代码中,很多了大佬还是使用了SGD-M方法,并没有使用Adam。关于这一点欢迎大家一起讨论。
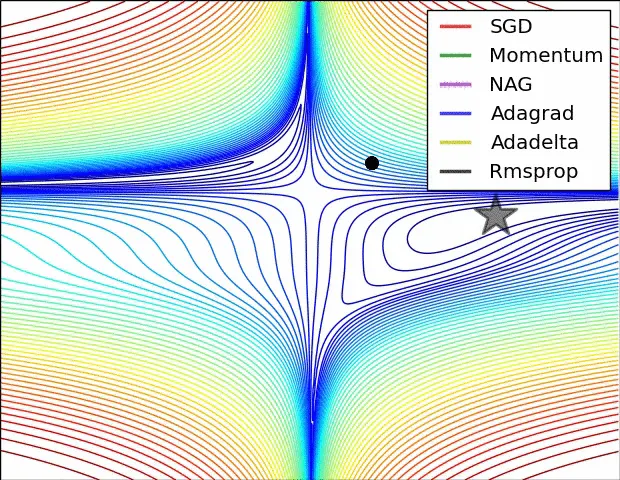
放一张经典的图