深度学习tricks汇总
网络结构
FPN(Feature Pyramid Networks )、SPP(spatial pyramid pooling)、ASPP(atrous spatial pyramid pooling)、FPN(Feature Pyramid Networks )、PAN(Pyramid Attention Network)、PSP(Pyramid Scene Parsing)或者Pyramid pooling module
SPP
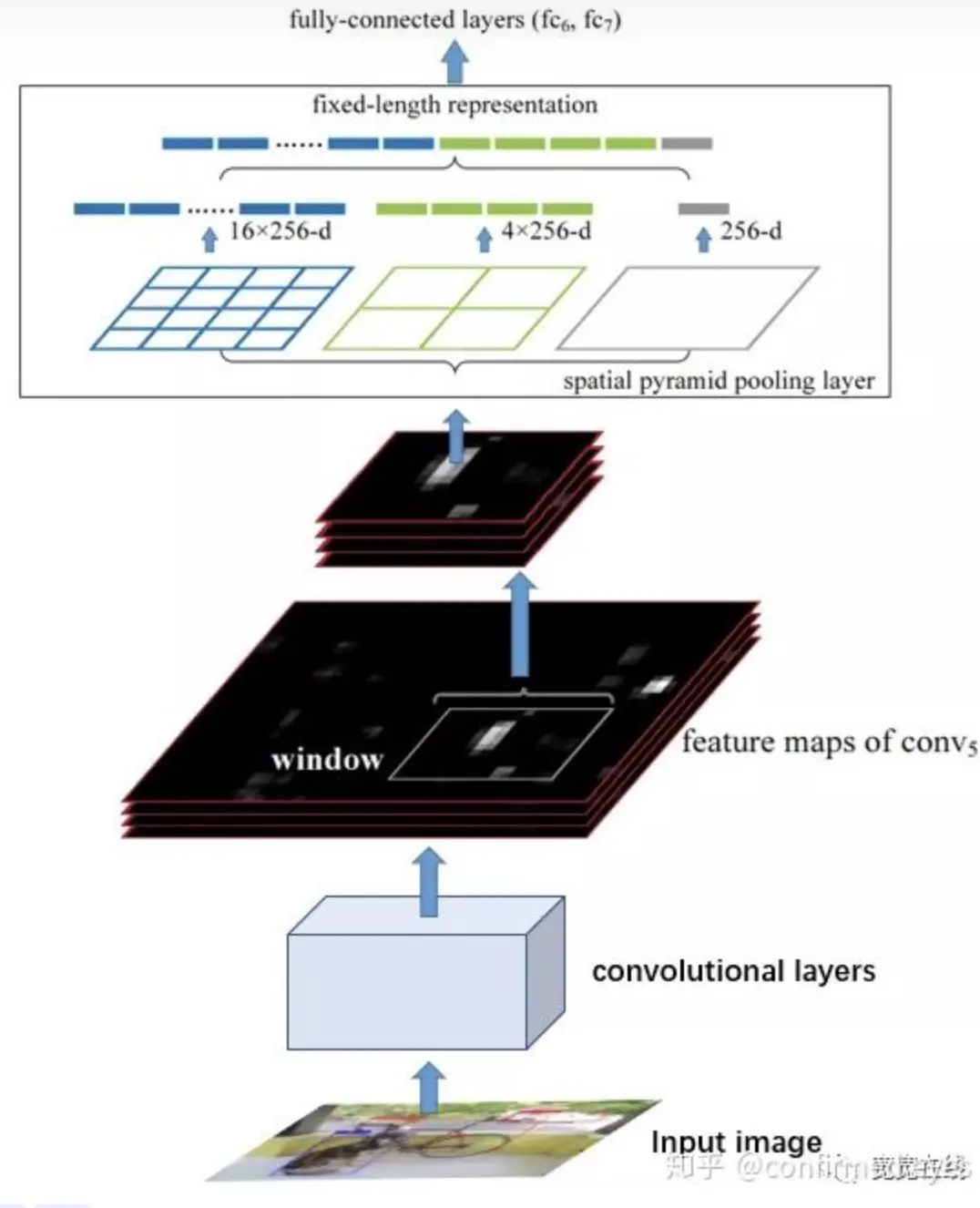 主要用于图像分类和目标检测中,其实和PSP网络结构设计思想一样(SPP提出在前,PSP提出在后),PSP用于语义分割
主要用于图像分类和目标检测中,其实和PSP网络结构设计思想一样(SPP提出在前,PSP提出在后),PSP用于语义分割PSP、PPM
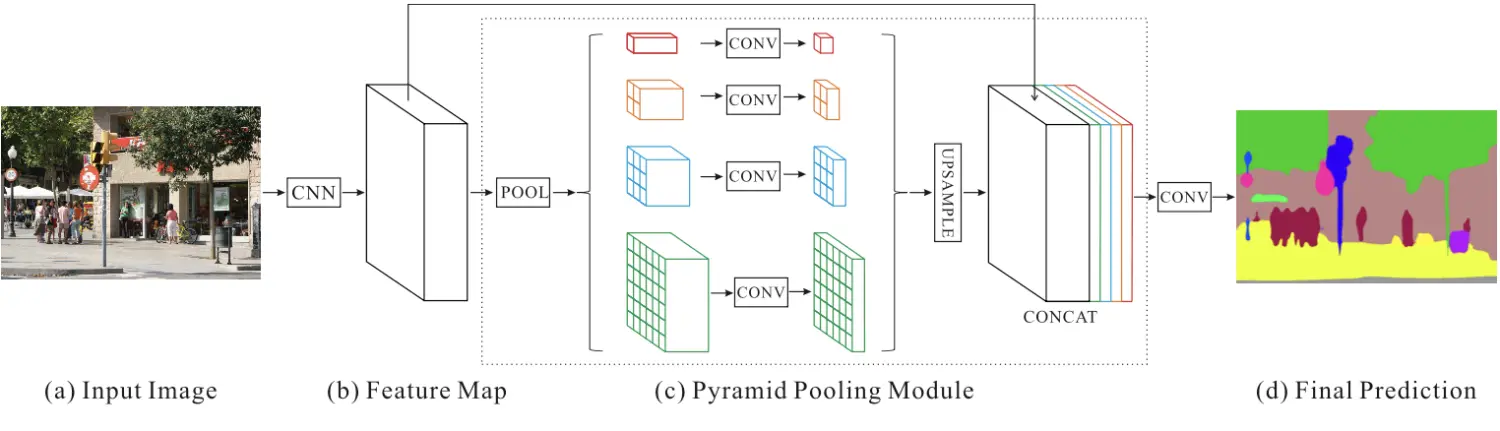 使用不同尺度的pooling操作(论文中最终输出的特征图尺寸为1*1,2*2,3*3,6*6),然后使用1*1的卷积将channel数降为原来的1/N (这里的N为4,目前是不过多的增加计算量),然后分别将输出上采样到原特征图大小,再concat拼接到一起
使用不同尺度的pooling操作(论文中最终输出的特征图尺寸为1*1,2*2,3*3,6*6),然后使用1*1的卷积将channel数降为原来的1/N (这里的N为4,目前是不过多的增加计算量),然后分别将输出上采样到原特征图大小,再concat拼接到一起FPN
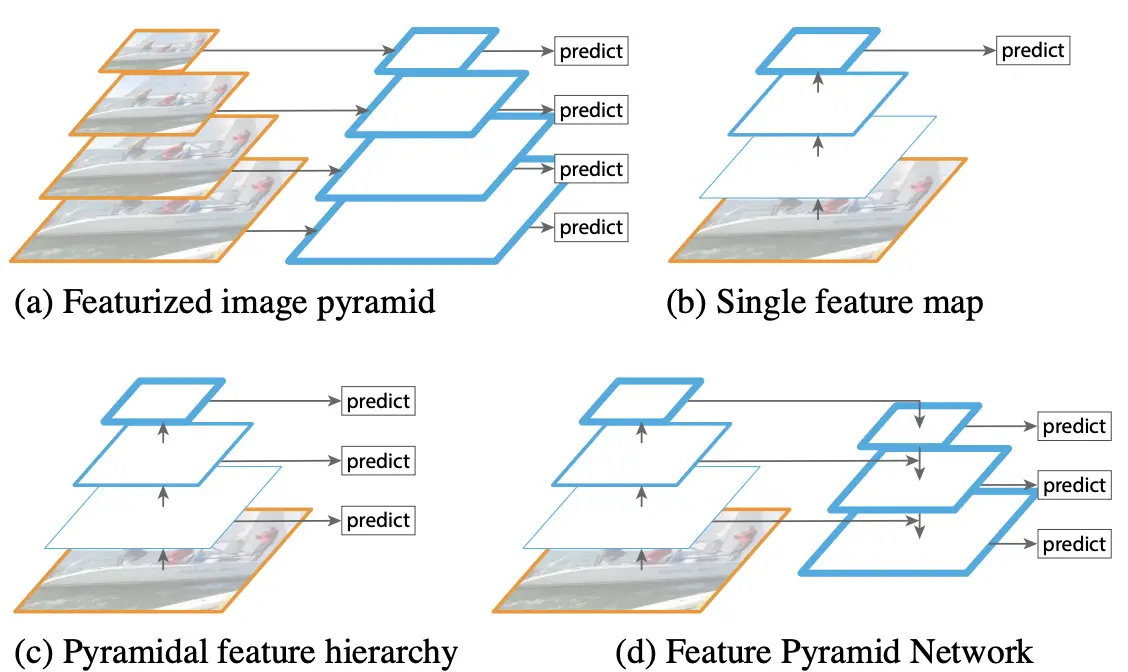 FPN如上图(d)所示
FPN如上图(d)所示PAN
整体结构:
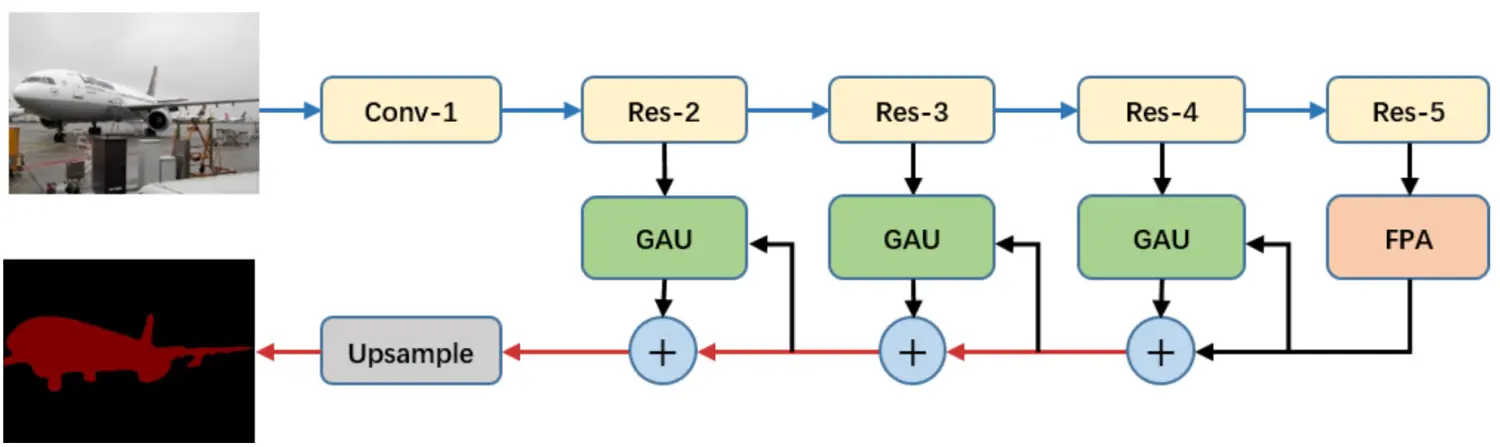 其中
FPA结构:
其中
FPA结构:
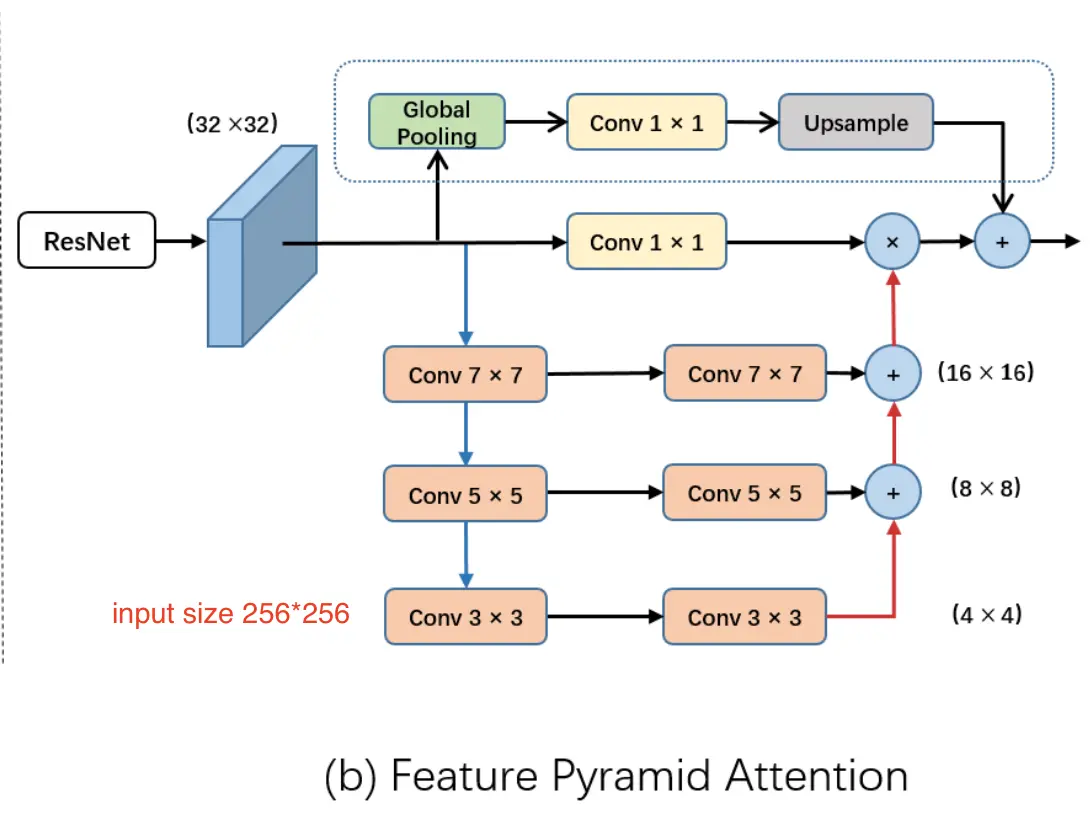 其中:
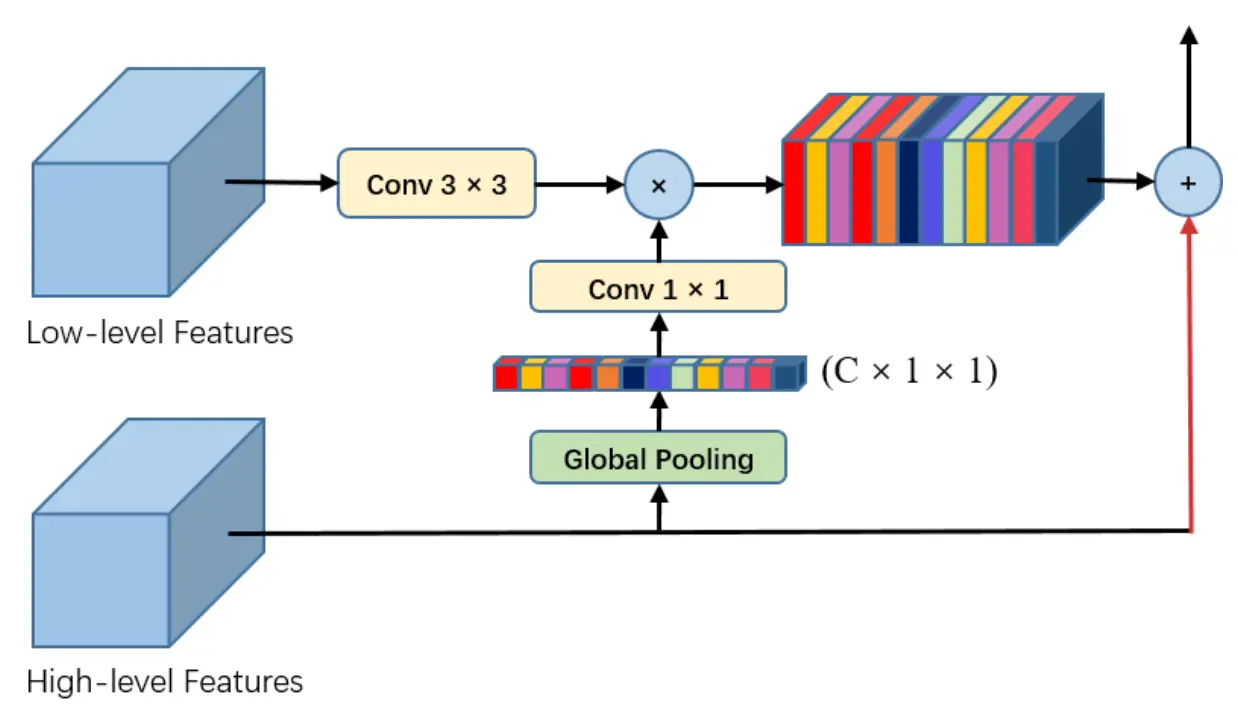
GAU结构:
其中:
GAU结构:
参考文档:
参考代码:
https://github.com/JaveyWang/Pyramid-Attention-Networks-pytorch
深度可分离卷积
损失函数
focal loss
$FL(p)=-(1-p)^\gamma log(p)$ 其中p为经过softmax后的输出。
当预测结果p越接近正确分类(接近1)的时候,会在原损失的基础上乘上$(1-p)^\gamma$的权重,该权重是一个比较小的值;相反如果预测结果p偏离正确分类的比较离谱,比如p结果0,那么$(1-p)^\gamma$就会比较大(相比于容易分的样本权重)。所以focal loss 在处理样本不均衡时候是一个比较不错的选择
smooth l1 loss $$loss = \left{ \begin{matrix} 0.5x^2, 当 x<1\ |x|-0.5, otherwise \end{matrix} \right. $$
- 改进了l2loss对异常比较敏感的问题(因为平方放大异常点的损失)
- 改进l1loss在零点不可能的问题
训练策略
- 学习率warmup
Warmup策略顾名思义就是让学习率先预热一下,在训练初期我们不直接使用最大的学习率,而是用一个逐渐增大的学习率去训练网络,当学习率增大到最高点时,再使用学习率下降策略中提到的学习率下降方式衰减学习率的值
- 学习率
在整个训练过程中,我们不能使用同样的学习率来更新权重,否则无法到达最优点,所以需要在训练过程中调整学习率的大小。
- 优化器的选择
带momentum的SGD优化器收敛速度较慢,但是初始化学习率设置合适,相对于其他自适应学习率的优化器如Adam、RMSProp等,可能取得更好的准确率;自适应学习率的优化器如Adam、RMSProp等,收敛速度往往比较快,但是最终的收敛精度会稍差一些。 如果追求更快的收敛速度,我们推荐使用这些自适应学习率的优化器,如果追求更高的收敛精度,我们推荐使用带momentum的SGD优化器。
其它
梯度弥散、爆炸
L1、L2 loss
l1 相比于 l2 为什么容易获得稀疏解?
参加如下链接中王赟的回答
关于正则
输入维度:(N,C, H, W)
BatchNorm:在(N,H,W)维度上做均值和方差的计算,均值和方差的输出维度为 (C)
Layer Normalization:在(C,H,W)维度上做均值和方差的计算,均值和方差的输出维度为 (N);对于NLP,输入维度是(N,L,H), Layer Normalization在H维度上做均值和方差的计算,输出维度(N,L)
Instance Normalization:在(H,W)维度上做均值和方差的计算,均值和方差的输出维度为 (N, C);对于NLP,输入维度是(N,L,H), Layer Normalization在L维度上做均值和方差的计算,输出维度(N,H)
Group Normalization:在(C/a, H,W)维度上做均值和方差的计算(C/a表示在channel上分组),均值和方差的输出维度为 (N, C/a)
RMS Normalization: 在Layer Normalization基础上改进,省去了平移,只计算方差。
初始化 Xavier初始化每一层输出的方差应该尽量相等
dropout 和 droppath
dropout: 随机丢弃一些神经元
droppath: 随机丢弃分支结构,使用如下
x = x+drop_path(net(x))非
x = drop_path(net(x))drop_path实现代码如下:
def drop_path(x, drop_prob: float = 0., training: bool = False): if drop_prob == 0. or not training: return x keep_prob = 1 - drop_prob shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device) random_tensor.floor_() # binarize output = x.div(keep_prob) * random_tensor return output输入是(B,C,H,W),droppath会随机将某一个样本全部变为0