对于模型的训练,训练的速度和显存的占用是必须要考虑的两个因素,特别是现在模型越来越大。1.4B的模型,在32GB的GPU上训练就会OOM。更别提现在动不动就几百B甚至上千B的模型。所以分析那些因素对模型的训练速度和显存的占用是十分必要的。
显存占用分析(训练阶段)
在训练阶段,显存被如下组件占用
- model weights
- optimizer states
- gradients
- forward activations saved for gradient computation
- temporary buffers
- functionality-specific memory
在ZeRO中model weights、optimizer states、gradients被称为模型状态(model states), 剩下的被称为剩余状态(residual states)
具体的计算如下(参数量假设为1)
model weights
- 4 bytes : fp32 training
- 6 bytes : mixed precision training(即需要保存一个float32参数,又需要保存一个float16参数)
Optimizer States
- 8 bytes:对于大模型优化器一般为AdamW(包含一阶梯度和二阶梯度,所以对于一个参数,优化器占用8个比特)
- 2 bytes:8-bit AdamW optimizer
- 4 bytes:SGD with momentum
Gradients
- 4 bytes: fp32 or mixed precision training (注:对于混合精度训练,一个参数的梯度,ZeRO论文任务是2 bytes(float16), Hugging face中认为梯度一般是4 bytes(float32)。)。所以这里不太确定,获取两种计算方式都是正确的(由框架实现决定)
所以,如果使用混合精度训练,一个参数,需要消耗18个bytes(6+8+4)(ZeRO认为16个bytes)
减少显存使用和提升训练速度的tricks
| Method | Speed | Memory | 备注 |
|---|---|---|---|
| Gradient accumulation | No | Yes | |
| Gradient checkpointing | No | Yes | |
| Mixed precision training | Yes | (No) | 不太严谨 |
| Batch size | Yes | Yes | |
| Optimizer choice | Yes | Yes | |
| DataLoader | Yes | No | |
| DeepSpeed Zero | No | Yes |
必要的解释
- Gradient accumulation: 对训练的速度无影响,减少了temporary buffers的使用
- Gradient checkpointing:一般来讲,激活函数的输出是要保存的,因为反向传播需要用到激活的输出值。这一部分也需要消耗不少的显存,Gradient checkpointing是一种时间换空间的技术,现象传播的过程中省略部分的激活值,反向传播的的时候重新计算
- Mixed precision training: 混合精度可以大大加快训练速度,但是没有减少model state部分的显存,但是激活值占的显存减少了,所以可能减少的量级不大,所以hugging face教程里写道对显存占用没有提升
- Batch size:当batch size或者输入输出神经元的数量可以被一个确定的数整除时候,通常可以获得最佳性能。这个数字通常是8,和数据类型和硬件也有关系,对于fp16,8的倍数是推荐值;对于A100, 64是推荐值
- Optimizer choice: 这个无需多解释
- DataLoader:将pin_memory(CPU中的一块区域,从cpu中的pin_memory将数据复制到GPU比直接从cpu复制到GPU要快)设置为True,调大num_workers都可以加快数据的加载速度。
- DeepSpeed Zero: 基本是大模型的标配,主要是讲Model States分块放在不同GPU上,下面会细讲。
关于混合精度
混合精度的示意图如下
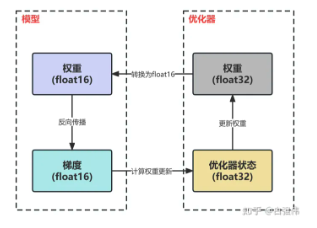 上文有提到混合精度训练没有减少model state部分显存的占用就是因为使用混合精度,虽然将参数和梯度的占用从4字节变到2字节,但是优化器需要保存一份float32版本的权重,所以总的来说没有减少model state部分显存的占用。
上文有提到混合精度训练没有减少model state部分显存的占用就是因为使用混合精度,虽然将参数和梯度的占用从4字节变到2字节,但是优化器需要保存一份float32版本的权重,所以总的来说没有减少model state部分显存的占用。
ZeRO(Zero Redundancy Optimizer)
ZeRO将显存占用优化分为三个阶段,如下示意图。
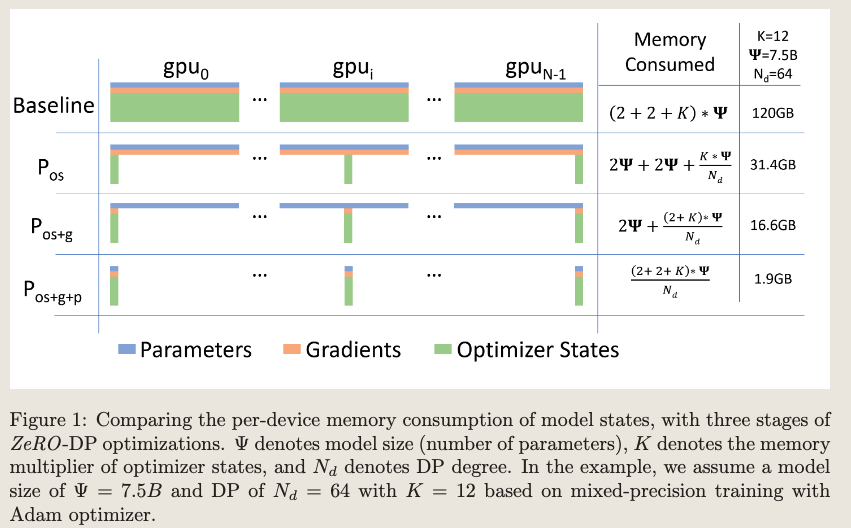 在ZeRO的实现框架比如DeepSpeed等,三个阶段可以分别配置优化。Huggingface已经将DeepSpeed集成,使用非常方便,所以建议直接使用Huggingface框架
在ZeRO的实现框架比如DeepSpeed等,三个阶段可以分别配置优化。Huggingface已经将DeepSpeed集成,使用非常方便,所以建议直接使用Huggingface框架