ELBO(Evidence Lower Bound)是变分贝叶斯推断(Variational Bayesian Inference)中的重要概念。其将推断问题转化为优化问题。那什么是变分推断呢?先补充一些概念(不了解不影响本文的阅读,大致知道就行)。
泛函(functional):通常是指定义域为函数集,而值域为实数或者复数的映射。换而言之,泛函是从由函数组成的一个向量空间到标量域的映射。
变分:变分与函数的微分类似,变分为定义在泛函上的微分。g(x)和新函数g(x)+m$\eta(x)$的差导致泛函的变化就叫变分。即 $$\delta J = J[g(x)+m\eta(x)]-J(g(x))$$ ,其中$\delta J$就是变分。
推断(inference):利用已知变量推测未知变量的分布,即求后验分布$p(y|x)$,但这个后验分布往往很难求得,所以实际中往往使用近似推断去求解。典型代表就是变分推断
变分推断:用一个简单分布区近似一个复杂分布,求解推断(inference)问题的方法的统称。
变分贝叶斯方法:通过将复杂的后验分布用一个更简单的分布来近似,并通过优化让它们尽可能接近。
preliminary
当给定一些观测数据x时,我们希望获得x的真实分布p(x)。但是p(x)是一个非常复杂的分布,我们很难直接获得或者优化。所以对于复杂问题,我们通常采用化烦为简的思路求解。p(x)难求解,我们就用简单的分别去拟合。即可以引入一些简单分布, 将p(x)转化为如下形式去求解。
$$ \begin{align} p(x) = \int_z p(x|z)p(z)dz \end{align} $$
其中p(z)是先验分布(先验分布的意思就是我们假设是已知的分布,比如我们就假设p(x)是标准正太分布),p(x|z)为条件概率。
我们这么理解上面的式子呢?我们借用ELBO中的例子(补充一句,强烈大家阅读这篇blog, 对ELBO的研究动机、原理都有比较清楚的解释,不想网上的很多文章上来给证明,完全不知道为什么要这么做,特别是对像我这种不理解前因后果就难受的人,是一种折磨)。
比如p(x)的分布是下面这个样子。
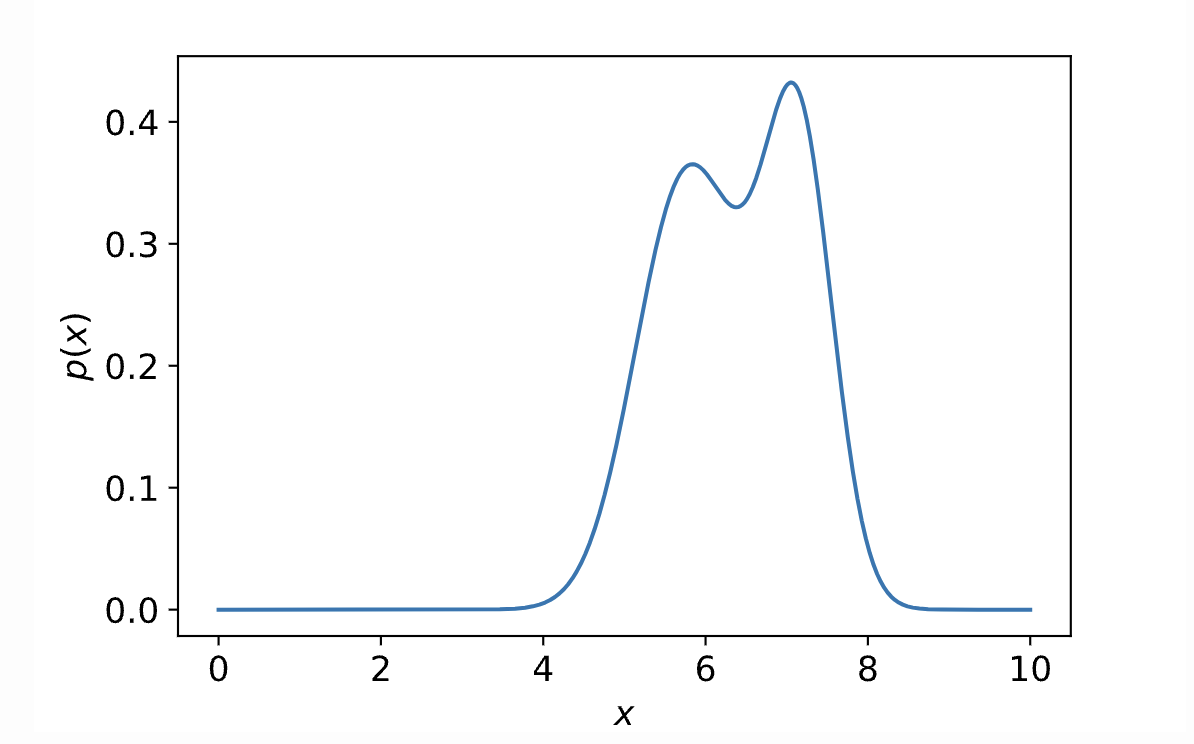
我们希望p(x)可以由一些简单分布变换而来。比如假设p(z)是一个简单高斯分布。
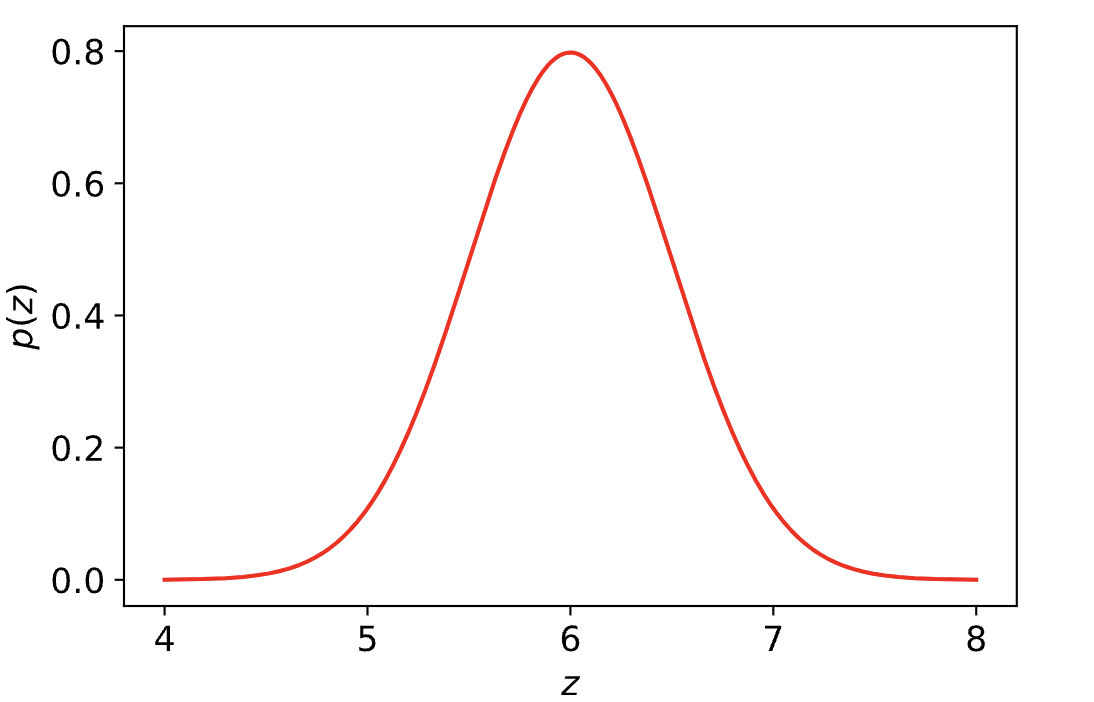
现在我们试着用p(z)加一些变换f(.)去拟合p(x)。
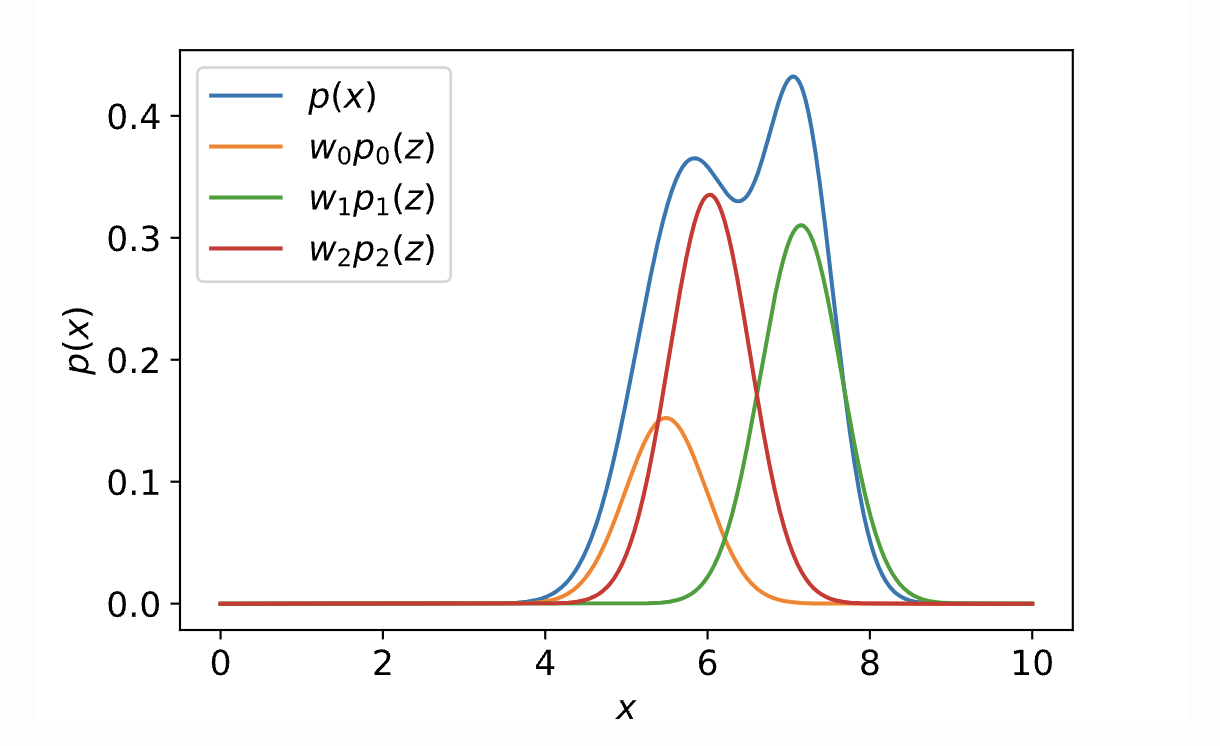
我们的出发点是好的,但是$p(x) = \int_z p(x|z)p(z)dz$依然是不可求解的。尽管我们把复杂分布解耦为简单高斯分布和高斯条件分布的乘积
原因有二。
- 这里有积分,在整个隐变量空间(且是连续的)进行积分是困难的。
- p(x|z)我们同样不知道。
对于问题2,容易解决,因为我们有神经网络啊,我们用参数为$\theta$的神经网络去估计p(x|z), 记为$p_\theta(x|z)$, 但是积分如何解决呢? 公式1中是对整个隐空间进行积分,搜索空间太大,而且我们还需要对个隐空间进行积分。因为我们对z不是一无所知。因为给定样本x,我们是可以获取一些z的信息的,即可以用$q_i(z)$去估计$p(z|x_i)$,但是对每一个观测数据都对应一个$q_i(z)$需要大量的参数(there is an obvious drawback behind this intuition. The number of parameters of qi(z) will scale up with the size of the set of observations because we build individual distribution after observing each data, 参考:ELBO)。所以再次引入神经网络$q_\phi(z|x)\simeq q_i(z) \forall x_i \in X$。$q_i(z)$的真实分布为$p(z|x)$。
ELBO(evidence lower bound, aka. variational lower bound)
上面说了一大堆,好像还是无法直接获得p(x)的分布。只知道现在要用$q_\phi(z|x)$ 去估计$p(z|x)$。ELBO将上诉的推断问题变成了优化问题。我先给出结论,后面再证明
$$ \begin{align} log\ p(x)&=E_{q_\phi(z|x)}[log\frac{p(x,z)}{q_\phi(z|x)}]+D_{KL}(q_\phi(z|x)||p(z|x)) \\ &=ELBO+D_{KL}(q_\phi(z|x)||p(z|x)) \\ &>=ELBO \end{align} $$
通过上式我们将求解log(p(x))问题转换为优化ELBO问题,因为我们希望p(x)的概率尽可能的大,只要让ELBO尽可能的大就好了。evidence lower bound中evidence就指的是log p(x), 对于观测数据而言,log p(x)是固定的。
目前还遗留两个问题,(1)ELBO的这么推导出来的,(2)ELBO如何优化
推导ELBO
前面我们提到要用$q_\phi(z|x)$ 去估计$p(z|x)$,那如何衡量这个估计的好坏呢?用KL散度。即$D_{KL}(q_\phi(z|x)||p(z|x))$,
注
- 网上有一些讲变分推断的用的$D_{KL}(q_\phi(z)||p(z|x))$开始推导ELBO的,即用简单分布$q_\phi(z)$去估计$p(z|x)$。但是我们是因为看VAE的资料才想搞明白ELBO的理论依据的,在VAE中ELBO是通过前者开始推导的(参见lilianweng的VAE blog)。所以这里我们从$D_{KL}(q_\phi(z|x)||p(z|x))$开始出发。
- 由于KL散度是不对称,这里的$D_{KL}(q_\phi(z|x)||p(z|x))$是反向KL散度,关于正、反向的KL散度可以查阅lilianweng的VAE blog和变分推断(Variational Inference)初探
开始证明
$$ \begin{align} D_{KL}(q_\phi(z|x)||p_\theta(z|x))&=\int q_\phi(z|x)\ log\frac{q_\phi(z|x)}{p_\theta(z|x)} dz \\ &=\int q_\phi(z|x)\ log\frac{q_\phi(z|x) p_\theta(x)}{p_\theta(z,x)}dz\\ &= \int q_\phi(z|x)[log\ p_\theta(x)+log\frac{q_\phi(z|x)}{p_\theta(z,x)}] dz \\ &=log\ p_\theta(x)+ \int q_\phi(z|x) log\frac{q_\phi(z|x)}{p_\theta(z,x)}dz \\ &=log\ p_\theta(x)-\int q_\phi(z|x) log\frac{p_\theta(z,x)}{q_\phi(z|x)}dz \\ &=log\ p_\theta(x)-ELBO \end{align} $$
所以 $$log\ p(x)=ELBO+D_{KL}(q_\phi(z|x)||p(z|x))$$
ELBO优化
上等式右边的第二项为KL散度(KL散度等于0),所以我们得到优化公式。 $$log\ p(x)>=ELBO$$
对ELBO进一步推导
$$ \begin{align} ELBO &= \int q_\phi(z|x) log\frac{p_\theta(z,x)}{q_\phi(z|x)}dz \\ &=\int q_\phi(z|x) log \frac{p_\theta(x|z)p_\theta(z)}{q_\phi(z|x)} dz\\ &=\int q_\phi(z|x)[log\frac{p_\theta(z)}{q_\phi(z|x)}+log p_\theta(x|z)] dz\\ &=-\int q_\phi(z|x)log\frac{q_\phi(z|x)}{p_\theta(z)}dz+\int q_\phi(z|x)log p_\theta(x|z)dz \\ &=-D_{KL}(q_\phi(z|x)||p_\theta(z))+E_{z\sim q_\phi(z|x)}logp_\theta(x|z) \end{align} $$
以上的推导与论文( Understanding Diffusion Models: A Unified Perspective)中推导一致。

最终对ELBO的直观理解见上图,ELBO的两项可以分别解读为
- 重建损失:$E_{z\sim q_\phi(z|x)}logp_\theta(x|z)$
- 正则:$D_{KL}(q_\phi(z|x)||p_\theta(z))$
ELBO的极大问题转变为重建损失和极小先验和后验的KL散度。
在VAE中,将$q_\phi(z|x)$建模为高斯分布。那么$q_\phi(z|x)$已知,$p(z)$是先验(标准正太高斯分布)。 即 $$ \begin{align} q_\phi(z|x)&=N(z;u_\phi(x), \sigma^2_\phi(x)I)\\ p(z)&=N(z;0,I) \end{align} $$
两个正太分布的KL散度是存在解析解的,所以ELBO可以优化。
参考文献
- Calvin Luo. Understanding Diffusion Models: A Unified Perspective
- From Autoencoder to Beta-VAE
- ELBO — What & Why
- 漫談 Variational Inference (一)
- The evidence lower bound (ELBO)
- 变分推断(Variational Inference)初探