(1) 关键概念
- world_size: 集群中所有GPU的数量
- rank: 范围[0, world_size-1], 表示GPU的编号
- local_rank: GPU在每台机器上的编号 比如,两台机器,每台机器4块卡,那么world_size= 2*4, rank 取值范围 [0,1,2,3,4,5,6,7], local_rank 取值范围[0,1,2,3]
(2) torch.distributed.launch 启动集群参数
- –nnodes: 一共多少台机器
- –node_rank: 当前机器编号
- –nproc_per_node: 每台机器多少个进程
- –master_adderss: master节点ip地址
- –master_port: master节点端口 master节点的node_rank必须为0
command example:
python -m torch.distributed.launch --nnodes=2 --node_rank=0 --nproc_per_node 8 \
--master_adderss $my_address --master_port $my_port main.py
- (3) mp.spwan 启动 PyTorch引入了torch.multiprocessing.spawn,可以使得单卡、DDP下的外部调用一致,即不用使用torch.distributed.launch。 python xxxx.py一句话搞定DDP模式。
def demo_fn(rank, world_size):
dist.init_process_group("nccl", rank=rank, world_size=world_size)
# lots of code.
...
def run_demo(demo_fn, world_size):
mp.spawn(demo_fn,
args=(world_size,),
nprocs=world_size,
join=True)
- (4) 集群训练步骤
import torch.distributed as dist
import torch.utils.data.distributed
from torch.nn.parallel import DistributedDataParallel as DDP
# local_rank 参数外部传入
parser.add_argument("--local_rank", default=-1, type=int)
FLAGS = parser.parse_args()
local_rank = FLAGS.local_rank
# (1)只有加入集群的GPU数量达到world_size时候,才会往下运行
torch.distributed.init_process_group(
backend='nccl', world_size=N, init_method='...'
)
# 构建数据集,要在DDP初始化之后进行
# DistributedSampler作用:将数据集分成多分,即每块卡的数据都是全量数据的一部分
train_sampler = torch.utils.data.distributed.DistributedSampler(my_trainset)
trainloader = torch.utils.data.DataLoader(my_trainset, batch_size=16, num_workers=2, sampler=train_sampler)
# (2) 构造模型, local_rank 外部传入
model = ToyModel().to(local_rank)
# (2.1)pretrain模型加载参数, 要在构造DDP模型之前,且只需要在master上加载就行了
if dist.get_rank() == 0 and ckpt_path is not None:
model.load_state_dict(torch.load(ckpt_path))
# (3)构造DDP 模型, DistributedDataParallel构造函数中回同步初始化参数,使集群中所有的gpu上的模型参数一致。所以如果是pretrain模型,需要在这个之前加载模型参数,见步骤(2.1)。多GPU模型(即一块GPU放不下一个模型,需要将模型放到不同GPU上)和CPU模型,device_ids,output_device必须为None
model = DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
loss_func = nn.CrossEntropyLoss()
model.train()
for epoch in range(xxxx):
# 不加该行代码,每块卡的同一个batch的数据是一样,加入该行代码,输入batch的样本顺序将会打乱
trainloader.sampler.set_epoch(epoch)
for data, label in trainloader:
data, label = data.to(local_rank), label.to(local_rank)
optimizer.zero_grad()
prediction = model(data)
loss = loss_func(prediction, label)
loss.backward()
iterator.desc = "loss = %0.3f" % loss
optimizer.step()
# DDP:
# 1. save模型的时候,和DP模式一样,有一个需要注意的点:保存的是model.module而不是model。
# 因为model其实是DDP model,参数是被`model=DDP(model)`包起来的。
# 2. 只需要在进程0上保存一次就行了,避免多次保存重复的东西。
if dist.get_rank() == 0:
torch.save(model.module.state_dict(), "%d.ckpt" % epoch)
其它细节
初始化方式
pytorch分布式训练初始化dist.init_process_group分为如下三种
Environment variable initialization
默认的初始化方式 dist.init_process_group(backend, init_method=‘file:///mnt/nfs/sharedfile’, world_size=4, rank=args.rank)
TCP initialization
dist.init_process_group(backend, init_method=‘tcp://10.1.1.20:23456’, rank=args.rank, world_size=4)
Shared file-system initialization
dist.init_process_group(backend, init_method=‘file:///mnt/nfs/sharedfile’, world_size=4, rank=args.rank)
Collective functions
Collective functions用于进程间通信,函数列表如下
broadcast
- 方法:torch.distributed.broadcast(tensor, src, group=None, async_op=False)
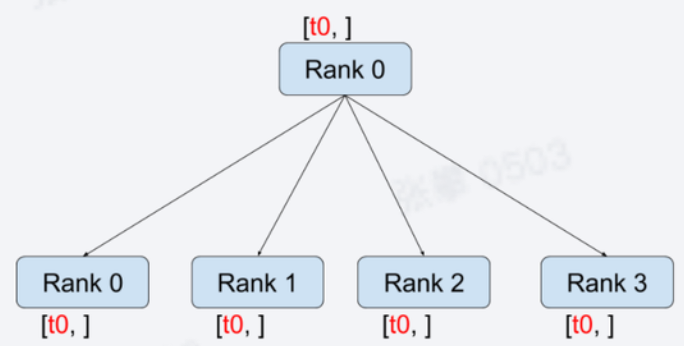
- 在src节点上将tensor广播到所有节点,所有节点的值是一样的
- 其它方法
- torch.distributed.broadcast_object_list(object_list, src=0, group=None, device=None): 支持python对象广播
- 方法:torch.distributed.broadcast(tensor, src, group=None, async_op=False)
scatter
- 方法: torch.distributed.scatter(tensor, scatter_list=None, src=0, group=None, async_op=False)
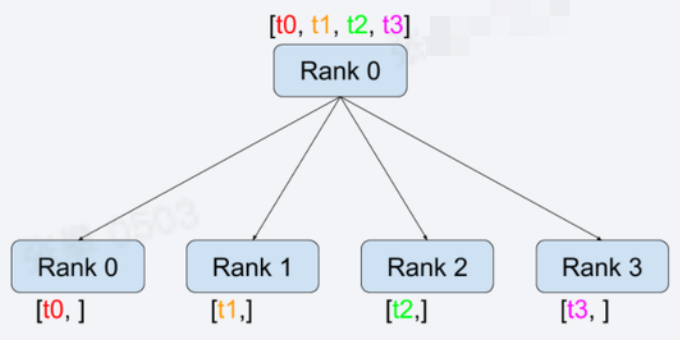
- 在src节点上将scatter_list中的值
依次传到其它节点,注意与broadcast的不同 - 其它方法
- torch.distributed.scatter_object_list(scatter_object_output_list, scatter_object_input_list, src=0, group=None):支持python对象
gather
- 方法:torch.distributed.gather(tensor, gather_list=None, dst=0, group=None, async_op=False)
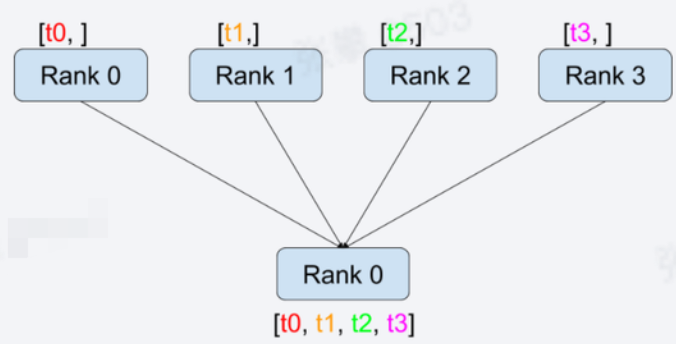
- 在dst节点上将每个节点上tensor收集到gather_list中
all_gather
- 方法:torch.distributed.all_gather(tensor_list, tensor, group=None, async_op=False)
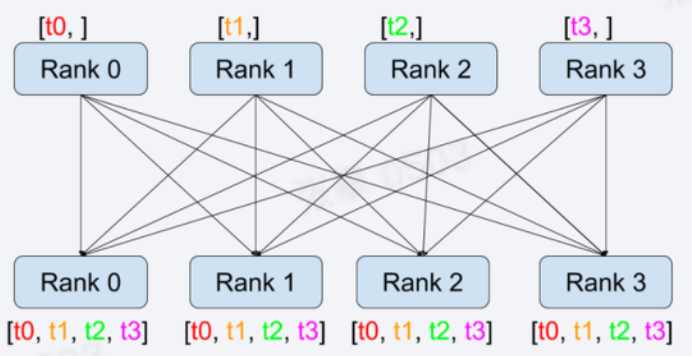
- gather是收集所有信息到指定节点,all_gather是收集所有信息到所有节点
reduce
- 方法:torch.distributed.reduce(tensor, dst, op=<torch.distributed.distributed_c10d.ReduceOp object>, group=None, async_op=False)
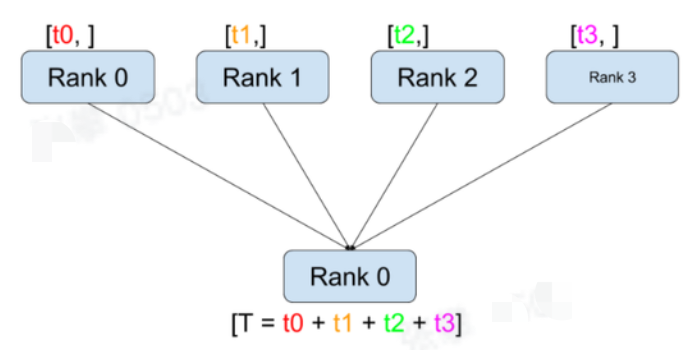
- 通过op(默认是求和)操作将信息进行归纳到dst节点,相当与数据库中group by, 其中op支持求和(sum)、最大(max)、最小(min)等
all_reduce
- 方法:torch.distributed.all_reduce(tensor, op=<torch.distributed.distributed_c10d.ReduceOp object>, group=None, async_op=False)
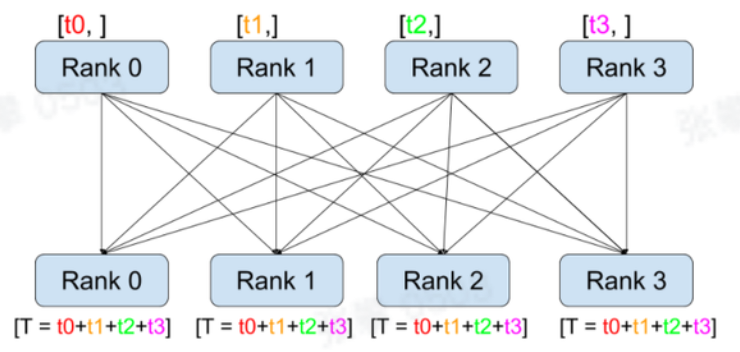
- 通过op(默认是求和)操作将信息进行归纳到所有节点
其它方法
- torch.distributed.all_gather_into_tensor(output_tensor, input_tensor, group=None, async_op=False):all_gather是放到list中,这里可以放到一个tensor中
- torch.distributed.all_gather_object(object_list, obj, group=None): 支持python对象
- torch.distributed.gather_object(obj, object_gather_list=None, dst=0, group=None):支持python对象
- torch.distributed.reduce_scatter(output, input_list, op=<torch.distributed.distributed_c10d.ReduceOp object>, group=None, async_op=False):先归纳再scatter
- torch.distributed.reduce_scatter_tensor(output, input, op=<torch.distributed.distributed_c10d.ReduceOp object>, group=None, async_op=False):Reduces, then scatters a tensor to all ranks in a group.
- torch.distributed.all_to_all(output_tensor_list, input_tensor_list, group=None, async_op=False):Each process scatters list of input tensors to all processes in a group and return gathered list of tensors in output list.
【参考文档】