Vanilla VAE( Autoencoder)
一、AutoEncoder 回顾
生成模型
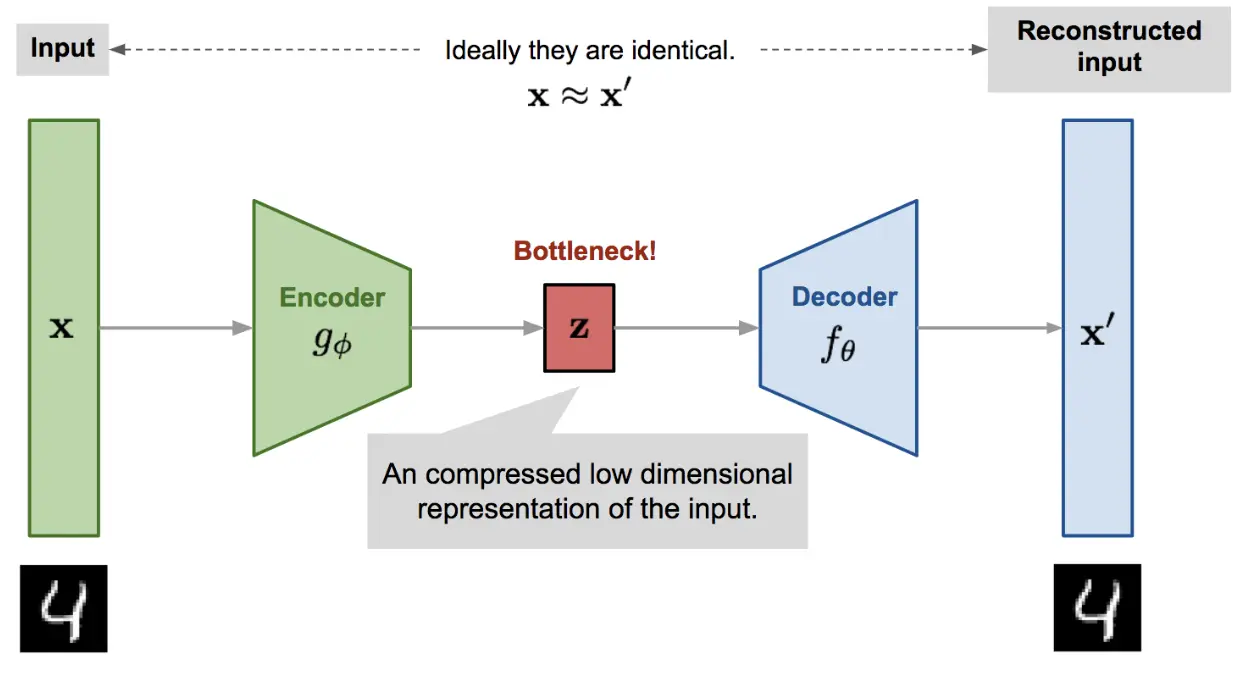
最理想的生成就是知道输入样本的分布$P(X)$, 然后我们并不知道该分布。那么可以近似求解。 $P(X) = \Sigma P(X|Z)*P(Z)$。但$P(X|Z), P(Z)$我们同样不知道。但是我们可以用神经网络去学习这两个分布。上图中的latent vector可以看成是$P(Z)$的一个采样,decoder可以看成条件概率$P(X|Z)$。但是我们真的可以采样一个z,然后用加一个decoder来作为我们的生成模型吗?
- z是Encoder对应着样本X的输出,如果我们直接用Decoder对z还原,那么最终得到的$\hat{X}$是和X是差不多的,我们需要生成模型是生成一个和X类似的,而不是一模一样的
- 如果对z做一些扰动,必然加一些噪声,那是不是就可以生成类似但是不一样的东西呢?理论上是可以,但是到目前为止,我们的模型并没有保证这一点(模型还没有学习)
加噪声是一个好的思路,如何加噪声?
让z从一个分布采样(注意不是直接使用encoder的输出),就是噪声。
那不放让z从一个$N(u, \sigma^2)$中采样。那需要知道$u, \sigma^2$, 既然不知道那就用神经网络生成吧。
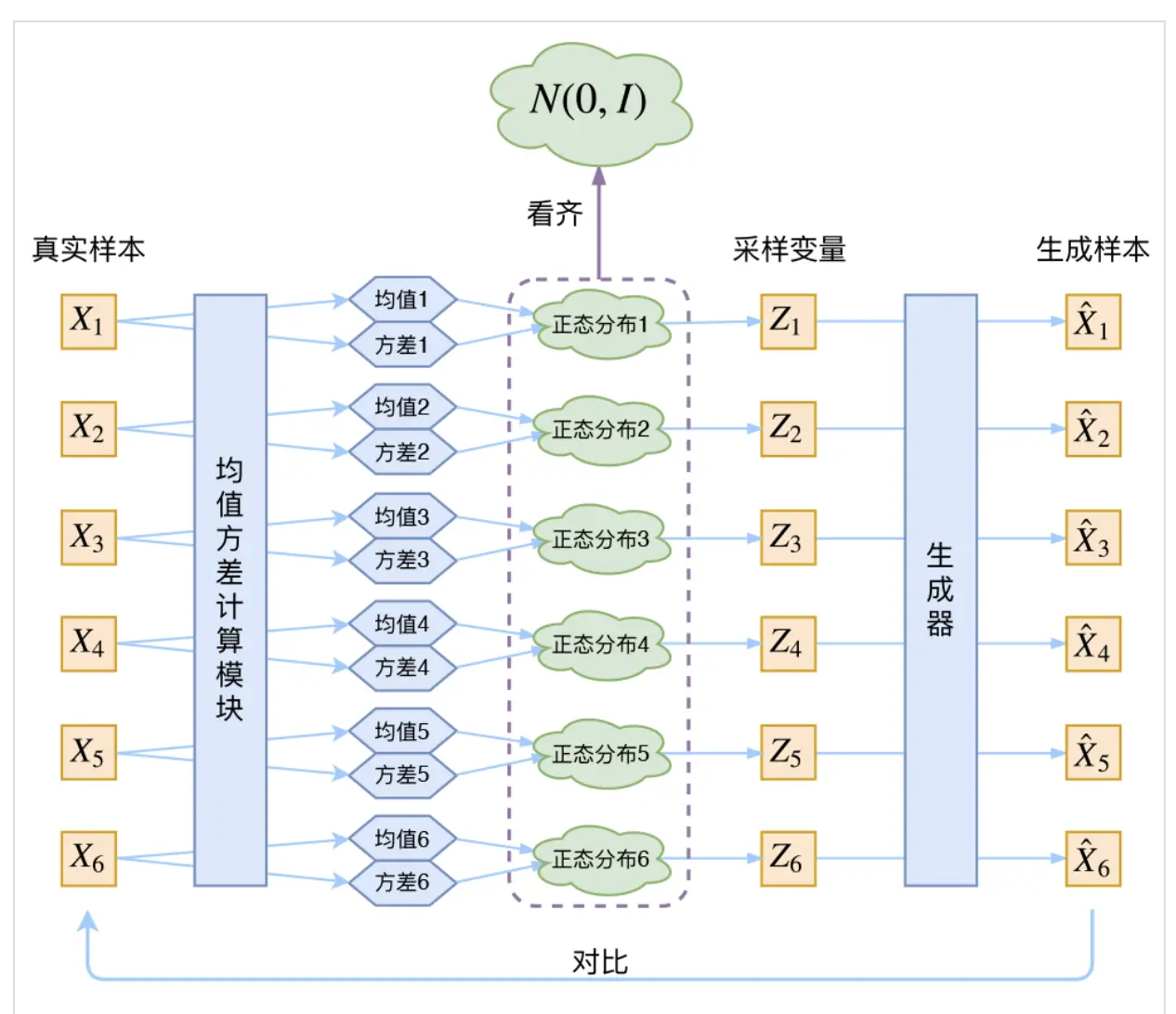
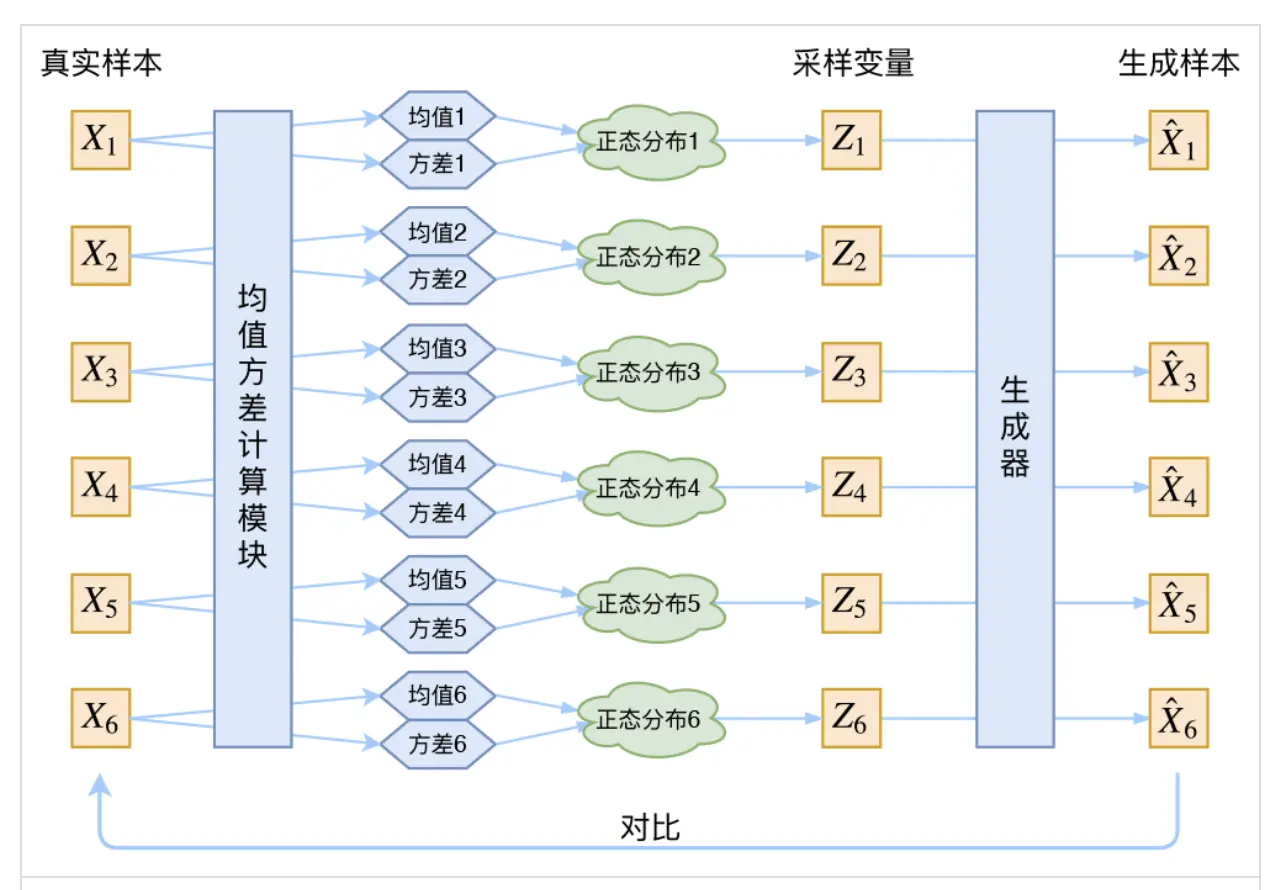 如果我们按照上述去训练我们的模型,生成的方差$\sigma^2$会倾向于变成0(因为容易学)。那如何加以限制?使z倾向于一个标准正态分布,即$\sigma^2$倾向于1。 如下图
如果我们按照上述去训练我们的模型,生成的方差$\sigma^2$会倾向于变成0(因为容易学)。那如何加以限制?使z倾向于一个标准正态分布,即$\sigma^2$倾向于1。 如下图
如何监督模型达到该目的,KL loss作为监督信号,KL loss如下
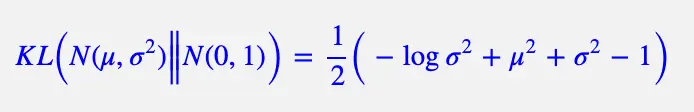
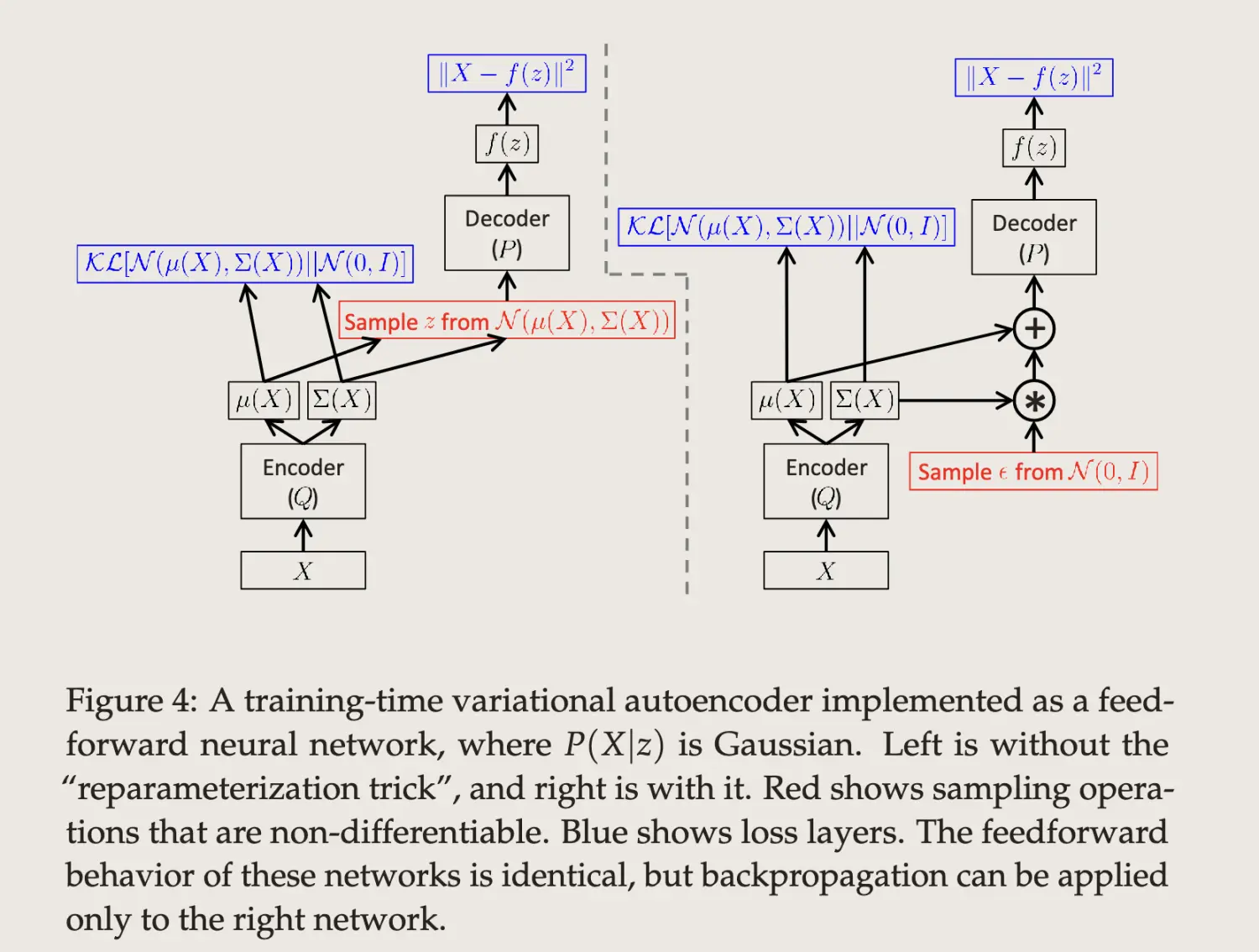
reparameterization trick
让z从$N(u, \sigma^2)$中采样,由于这个操作是不可导的,所以需要使用重采样技巧去解决不可导的问题。
$$z \sim N(u, \sigma^2) \iff z \sim u+\sigma^2 \times \epsilon$$ ,其中$\epsilon \sim N(0,1)$
思考?
- 为什么要正态分布、其它分布可否?
Variational Bayes
什么是变分贝叶斯推断?将贝叶斯后验概率计算问题转化为一个优化问题(计算->优化)。本章节汇总记录一些概念,上面讲解的部分已经可以支撑去训练一个VAE模型了,但是如果还不知道VAE中Variational的含义就有点说不过去了,我本来以为Variational是一个简单的概念,但是了解后发现并不简单,涉及一个数学分支。所以下面就记录一些涉及的相关概念,有助于大家的理解。后续我有新的认知会进一步完善。
泛函(functional)
定义1:泛函(functional)通常是指定义域为函数集,而值域为实数或者复数的映射。换而言之,泛函是从由函数组成的一个向量空间到标量域的映射。
定义2:设C是函数的集合,B是实数集合;如果对C中的任一个元素y(x),在B中都有一个元素J与之对应,则称J为y(x)的泛函,记为J[y(x)]。
通俗的讲泛函就是函数的函数,对于函数的定义我们再熟悉不过了,y = f(x),其中x是一个数值(定义域),y是一个数值(值域),f为映射关系。如果将x变成一个函数集合,那么就称之为泛函,即f[g(x)]。
变分(variational)
变分与函数的微分类似,变分为定义在泛函上的微分。g(x)和新函数g(x)+m$\eta(x)$的差导致泛函的变化就叫变分。即 $$\delta J = J[g(x)+m\eta(x)]-J(g(x))$$ ,其中$\delta J$就是变分。
变分法(Calculus of Variations or variational method)
使用变分来找到泛函的最大值和最小值的方法
变分推断(Variational Inference)
推断(inference):利用已知变量推测未知变量的分布,即求后验分布$p(y|x)$,但这个后验分布往往很难求得,所以实际中往往使用近似推断去求解。典型代表就是变分推断
变分推断:用一个简单分布区近似一个复杂分布,求解推断(inference)问题的方法的统称。
….. 待补充完善
参考文献
- Auto-Encoding Variational Bayes
- Tutorial on Variational Autoencoders
- 变分自编码器
- 李宏毅深度生成模型
- 泛函的概念
- 变分(Calculus of variations)的概念及运算规则(一)
- Variational Inference
- 变分推断(Variational Inference)初探