- Title: LoRA: 大语言模型的低秩适配
- 作者: {edwardhu, yeshe, phwallis, zeyuana, yuanzhil, swang, luw, wzchen}@microsoft.com yuanzhil@andrew.cmu.edu
- 发表日期:2021.10
该论文试图解决什么问题?
提出一个大模型的低秩适配方法去解决全量微调大模型时候需要全量更新模型参数、显存占用很大的问题。
Key Contributions
- 对于不同的下游任务,大模型的参数是共享的,变化的只不过是LoRA方法新引入的参数(即B、A参数矩阵)。所以如果有比较多的下游任务,大模型参数只需要保存一份,切换任务的时候也只需要切换一下B、A矩阵即可。大大减少了模型存储的空间和任务切换时候的负载
- LoRA方法可以使训练更有效(耗时减少)、减少3倍的显存使用。因为不用保存原始大模型参数的梯度。eg,GPT-3训练需要1.2T显存,使用LoRA方法显存只需要350G左右
- 不增加推理耗时(上面已经提到)
- 可以和其他的适配方法结合,比如prefix-tuning
Abstract & Introduction & Method
NLP模型使用的一个通用范式是先选择一个大的在通用数据集上训练的预训练模型,然后再在一个特定任务上做fine-tune。 但是如果做全量的fine-tune,就要更新模型所有的参数。比如GPT-3有1750亿的参数。fine-tune需要更新1750亿的参数,这个操作是昂贵的。本文提出一个名为LoRA(Low-Rank Adaption)的方法:freeze 预训练模型的参数,在原有的模型结构中插入低秩分解矩阵(rank decomposition matrices). 该方法可以极大的减少模型的训练参数。
- 方法示意图如下
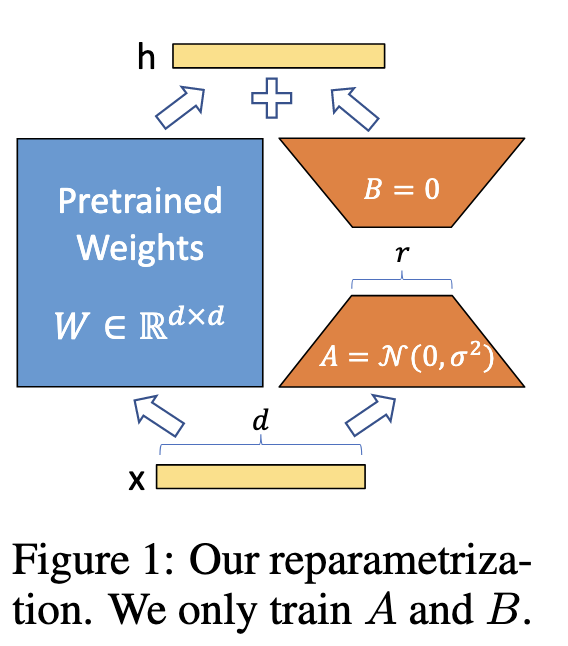
右边橙色的为新引入的可训练的低秩矩阵,其它的为原始模型的参数。数学表达可能更清楚一点。原始模型的前向过程表达为
$$h = W_0x$$, 修改后的前向过程如下:
$$h = W_0x+\Delta Wx=W_0x+BAx$$
LoRA核心的方法就是改公式。在模型保存的时候可以将$W_0+\Delta W$保存(即加起来),所以改方法不会增加模型的推理耗时
Experiments
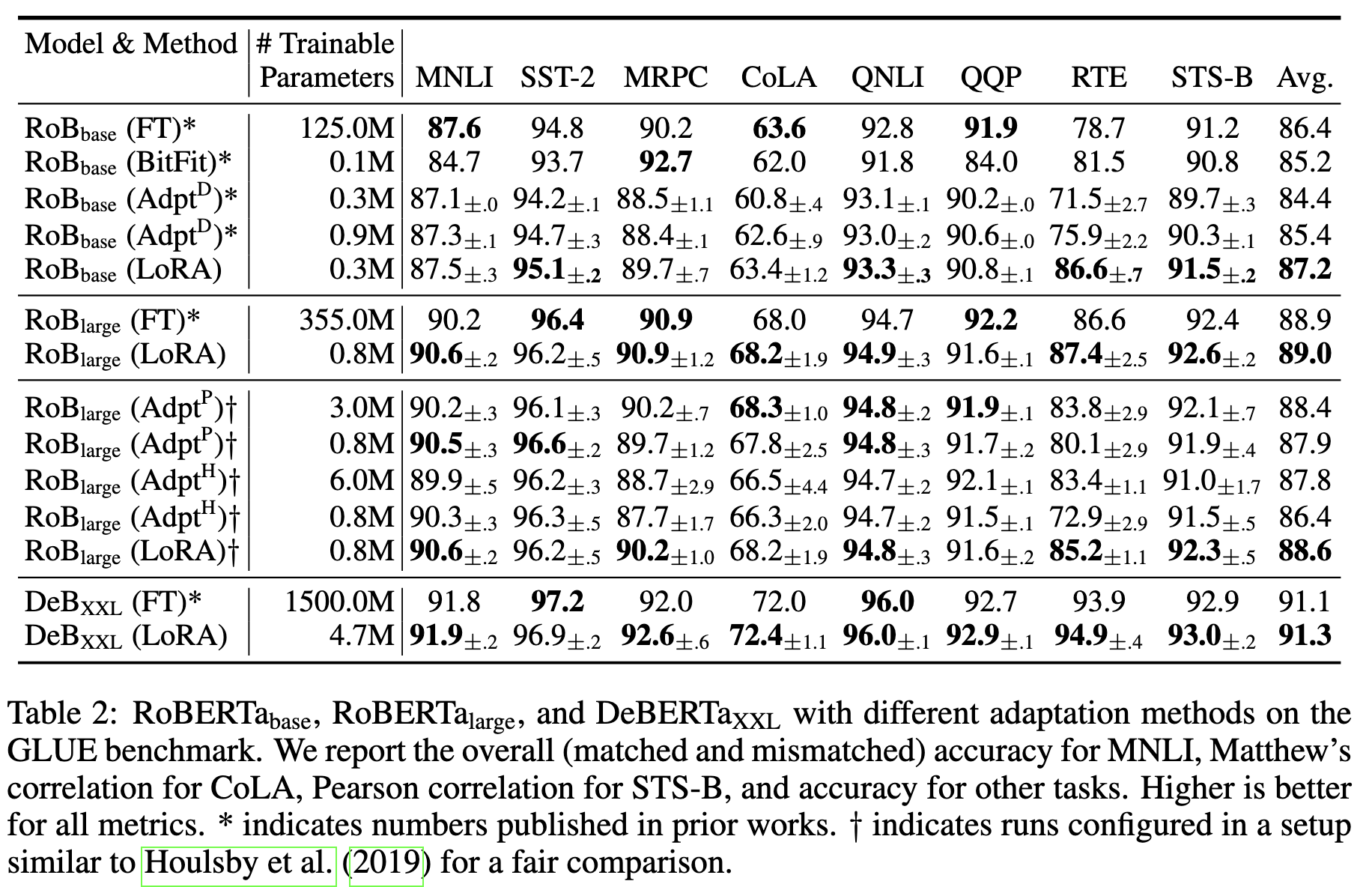
与不同适配方法在GLUE上的对比
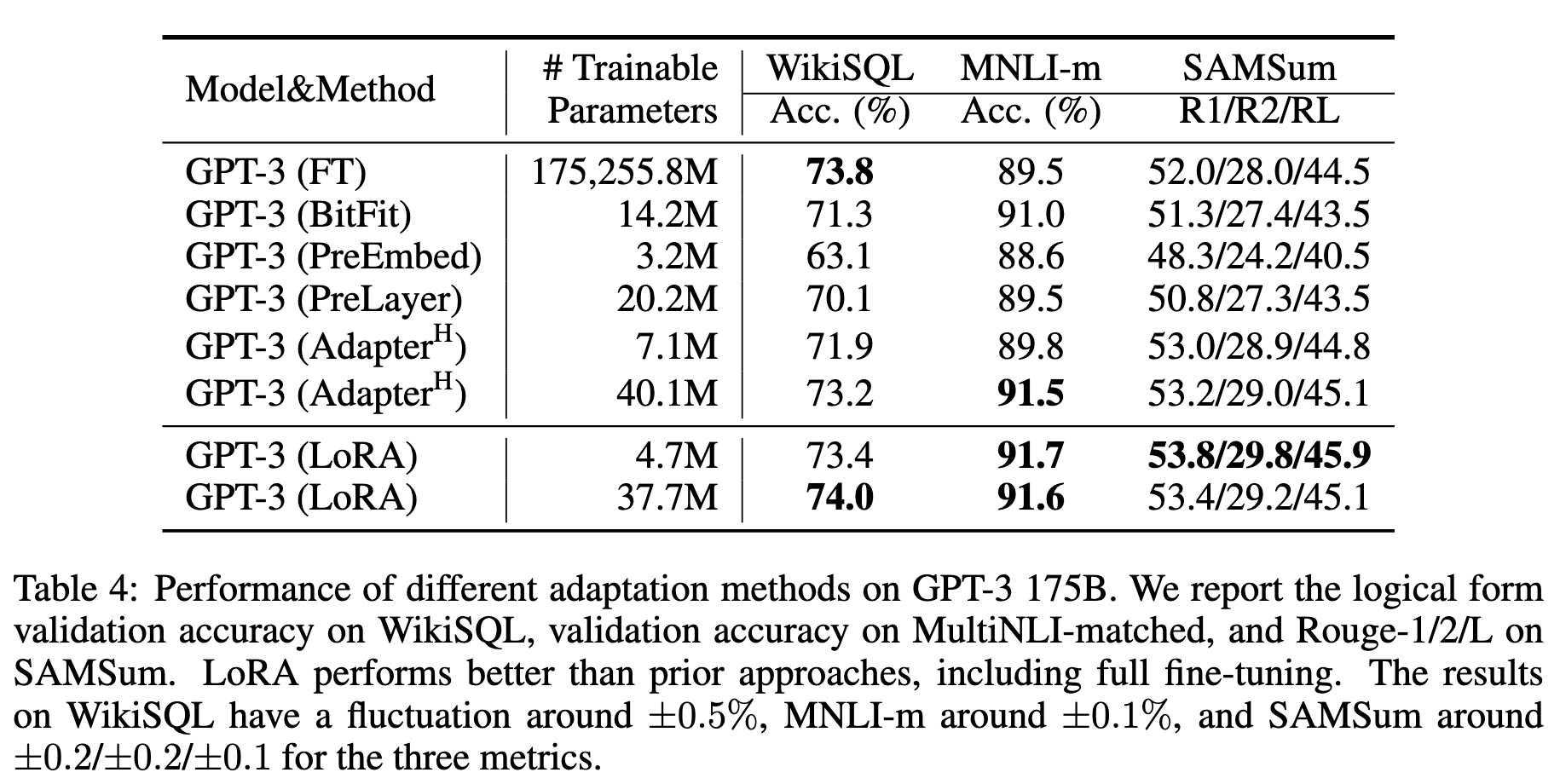
在GPT-3上的适配效果对比
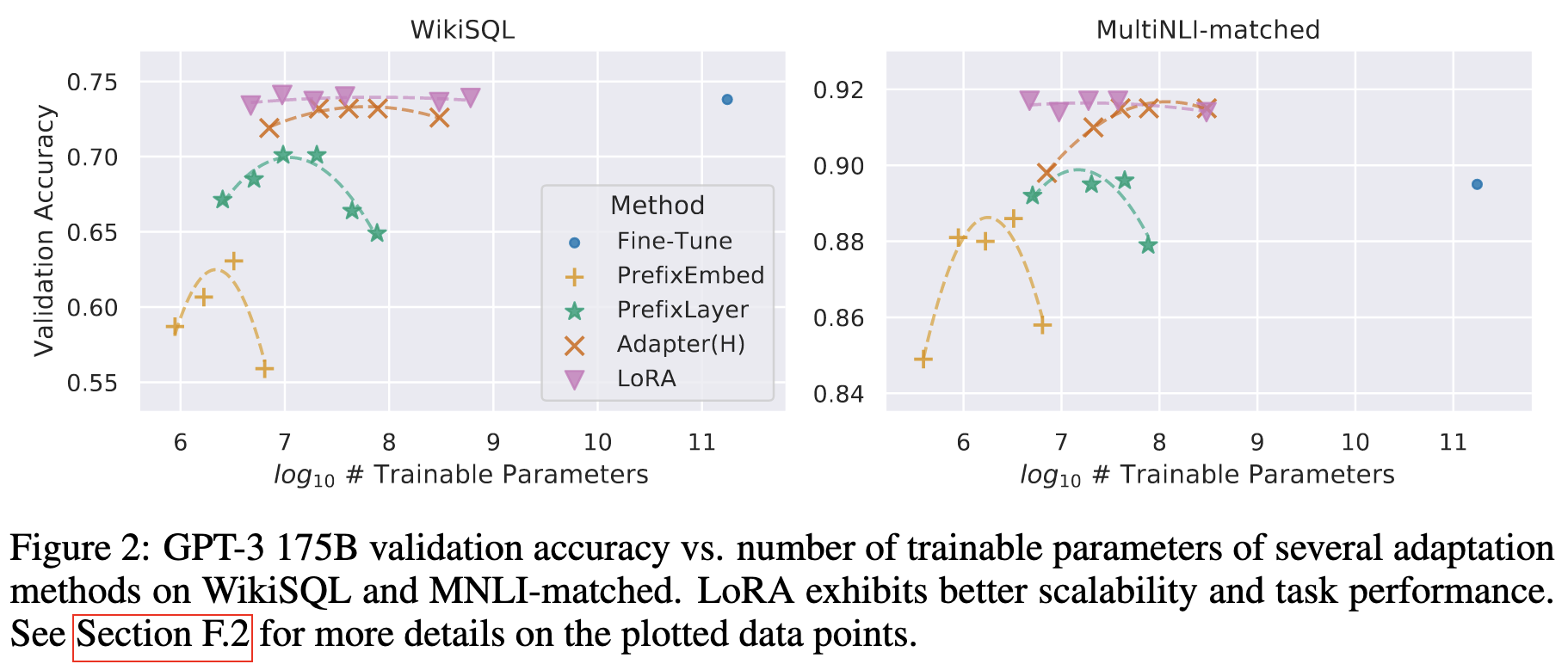
不同方法加大可训练参数量效果对比
Transformer结构为例,LoRA加到哪里更有效?
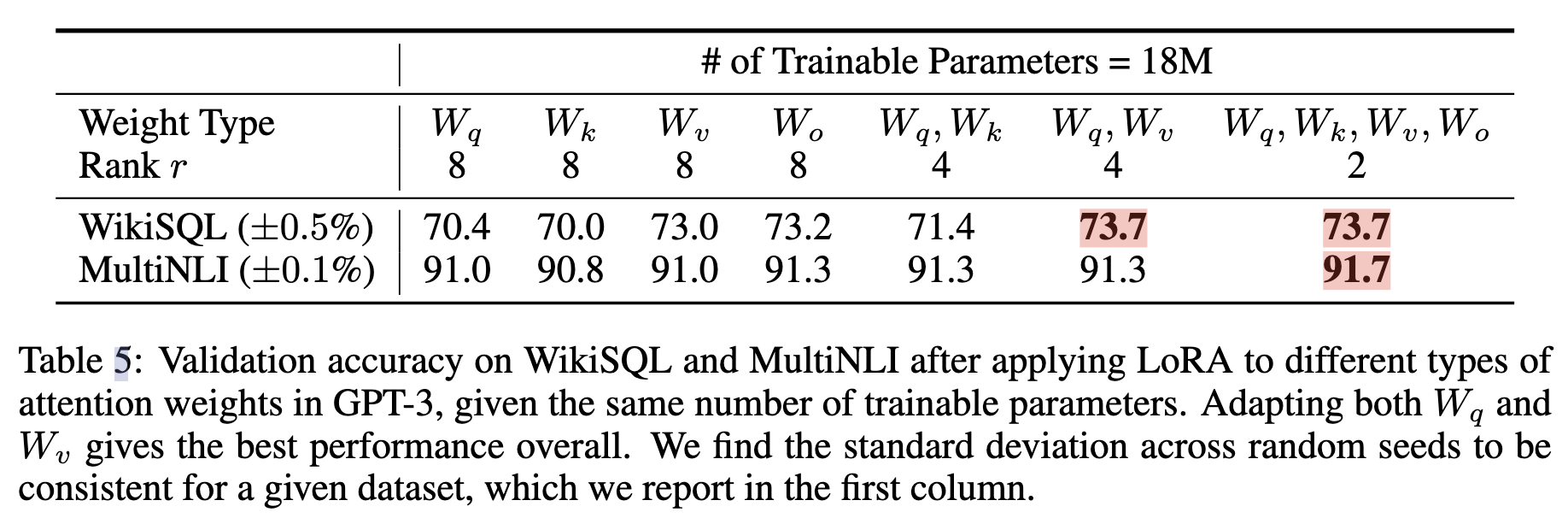 参数总量不变(秩r改变),加的地方不一样。实验表明加到$W_q$,$W_v$上效果更好
参数总量不变(秩r改变),加的地方不一样。实验表明加到$W_q$,$W_v$上效果更好r是不是越大越好?
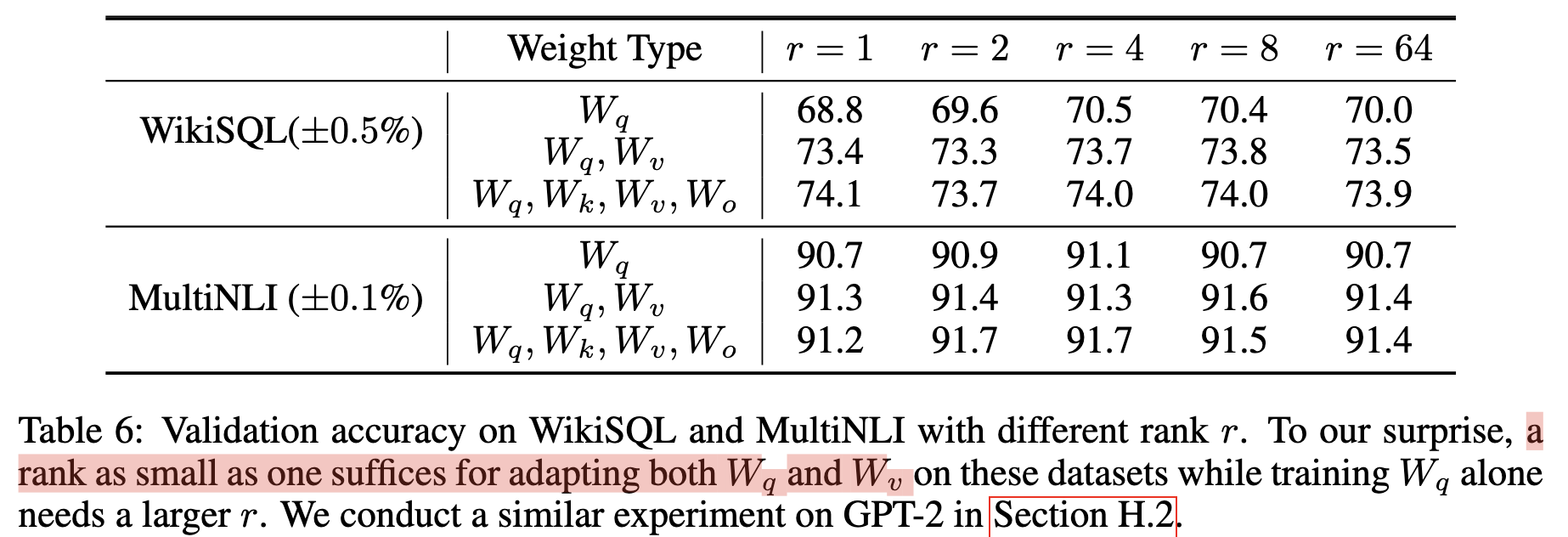 实验表明,r并不是越大效果越好,对于一些任务,r=4就足够了(取1效果也不错)。对于这个结论论文有一些说明,大致的意思就是r=4的时候,参数量已经够要学习的信息了,再打也是无非是引入冗余的信息罢了。这里解析的可以有失偏颇,感兴趣的参见原文为好。
实验表明,r并不是越大效果越好,对于一些任务,r=4就足够了(取1效果也不错)。对于这个结论论文有一些说明,大致的意思就是r=4的时候,参数量已经够要学习的信息了,再打也是无非是引入冗余的信息罢了。这里解析的可以有失偏颇,感兴趣的参见原文为好。
CONCLUSION AND FUTURE WORK
关于未来的工作方向。
- LoRA可以和其他迁移方法结合
- fine-tuning或者LoRA背后的机制是不清楚的,如何将在预训练的时候学习到的特征迁移到下游任务?作者认为LoRA比full fine-tuning做更好。
- 作者将LoRA添加到参数矩阵,是通过穷尽、实验的方式,有没有更好的指导原则?
- 既然LoRA可以通过添加一个低秩的矩阵就可以取到好的效果,那么原始的参数矩阵是不是也可以降低一下秩?。
第4点确实是一个比较好、且重要的研究方向。