- Title: BLIP-2: 用冻结的图像编码模型和大语言模型引导文本-图像预训练
- 作者: Junnan Li Dongxu Li Silvio Savarese Steven Hoi;Salesforce Research
- 发表日期:2023.5
- github: https://github.com/salesforce/LAVIS/tree/main/projects/blip2
该论文试图解决什么问题?
由于端到端的训练, 预训练视觉-语言模型代价变的非常高昂。这篇论文提出了BLIP-2, 一个通用的、有效的预训练策略: 其从现成的冻结的视觉模型和冻结的大语言模型,引导视觉-语言(vision-language)模型的预训练。该方法解决的跨模态对齐(视觉模型和LLM)问题。
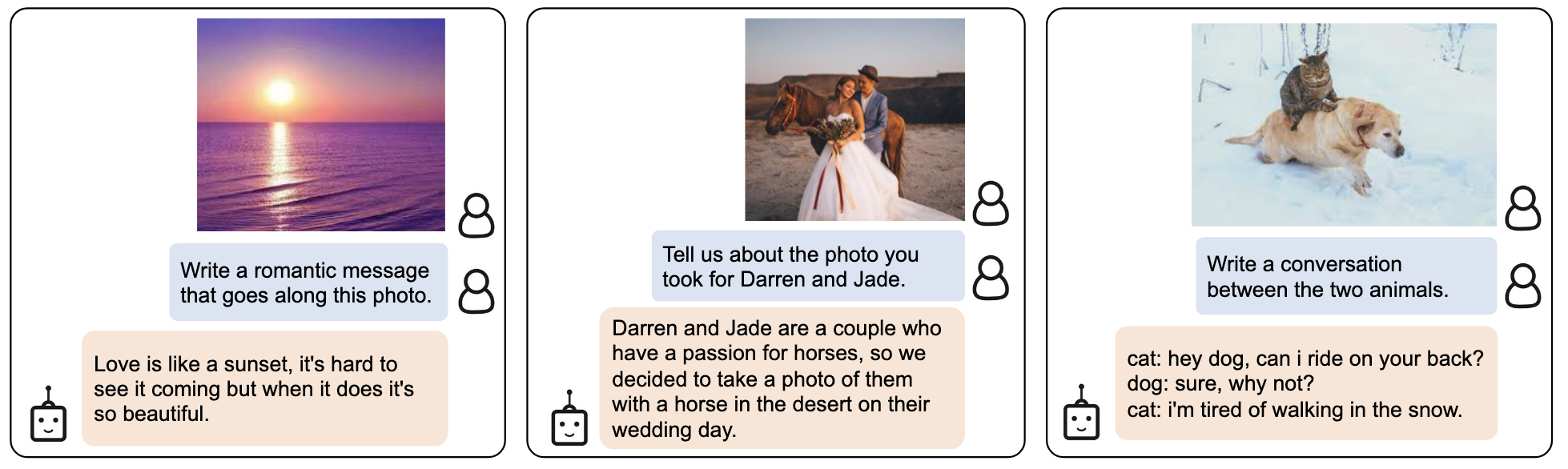
应用:Instructed Zero-shot Image-to-Text Generation
先展示一下BLIP2的强大能力,这是BLIP2最亮眼的地方。
- 信息检索能力,利用LLM强大的知识库

- 事实推理能力
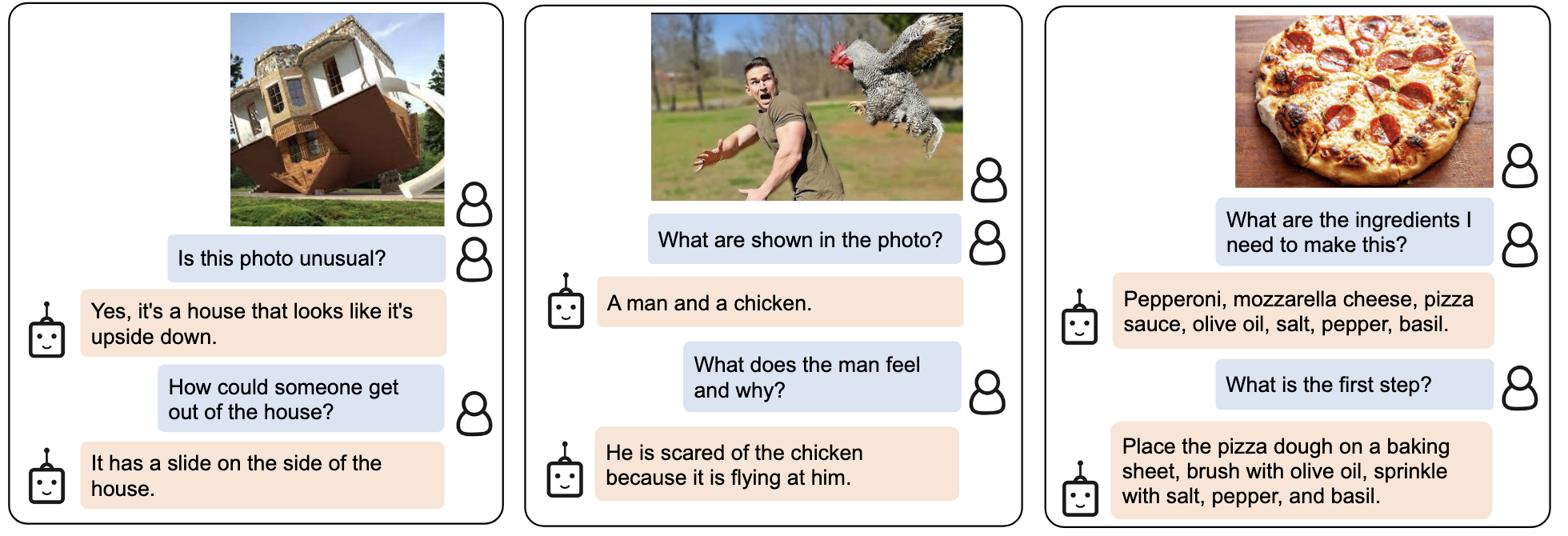
- 开放生成能力
Method
整体架构
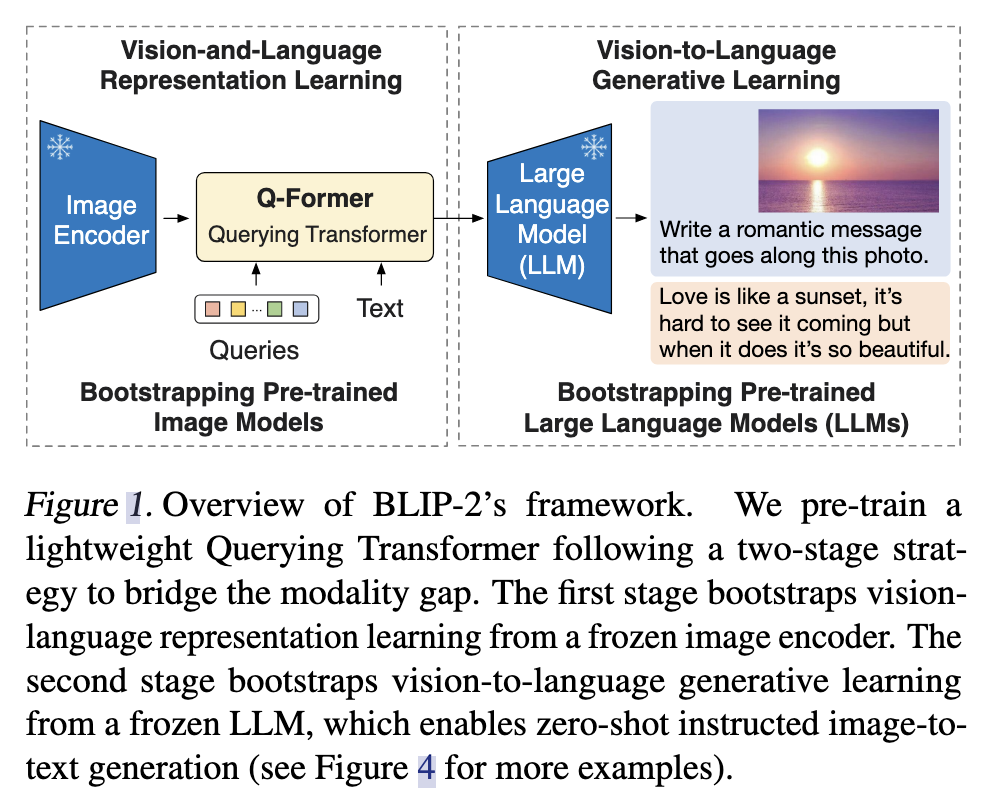
两阶段策略,预训练一个轻量级Q-Former模块去连接两种模态的gap。
第一阶段:从一个frozen image encoder中引导vision-language表示学习(representation learning)。
第二阶段:从一个frozen LLM中引导vision-to-language的生成学习(generative learning)
第一个阶段:图片-文本表示学习(vision-language representation learning)
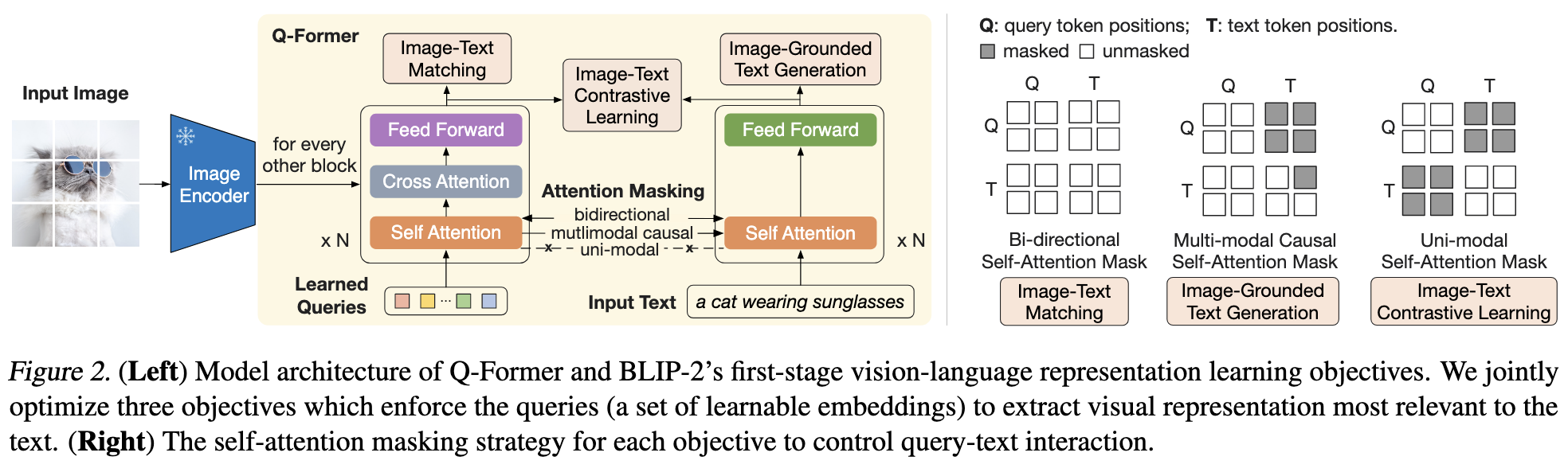
note: Q-Former的输出维度Z(32*768)远远小于VIT-L/14(257*1024)的维度 注意三个目标self-attention mask的不同
Q-Former作用:从图片中提取与文本最相关的特征
第二个阶段:图片到文本生成学习(vision-to-language generative pre-training)
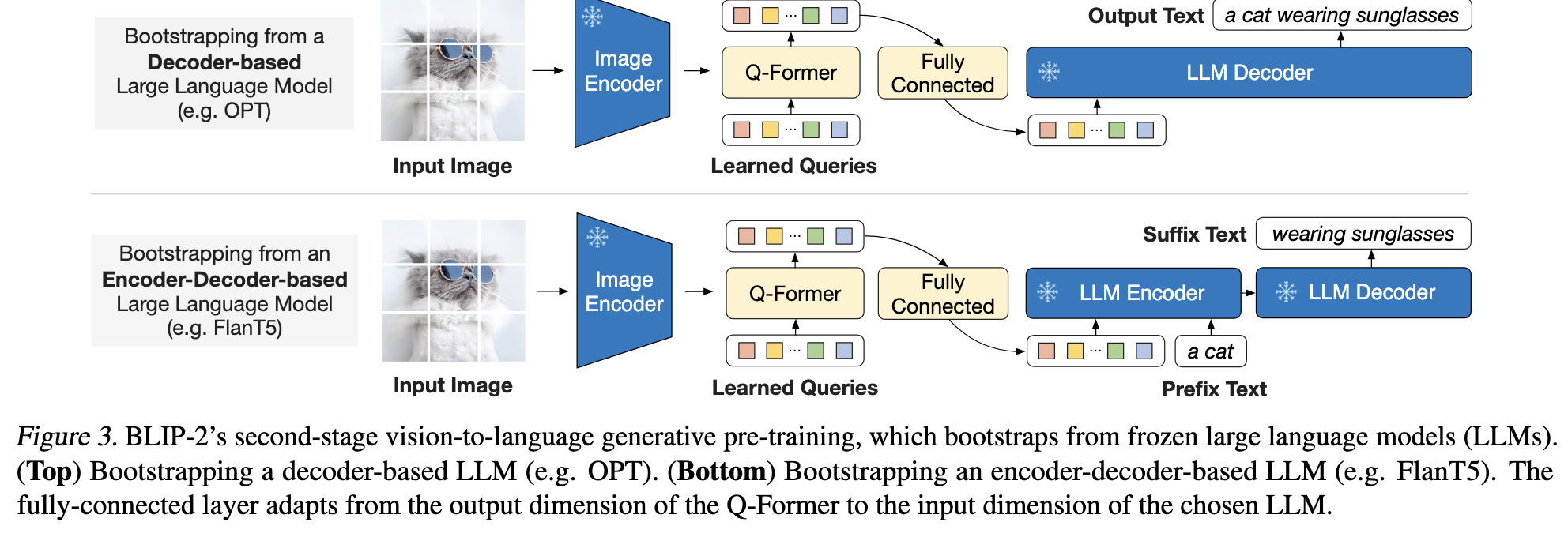 Q-Former后接入一个全连接层,用于使用LLM的输入。LLM model分为两类,一个像OPT只有Decoder模块,一个像FlanT5既有Encoder又有Decoder模块。
Q-Former后接入一个全连接层,用于使用LLM的输入。LLM model分为两类,一个像OPT只有Decoder模块,一个像FlanT5既有Encoder又有Decoder模块。
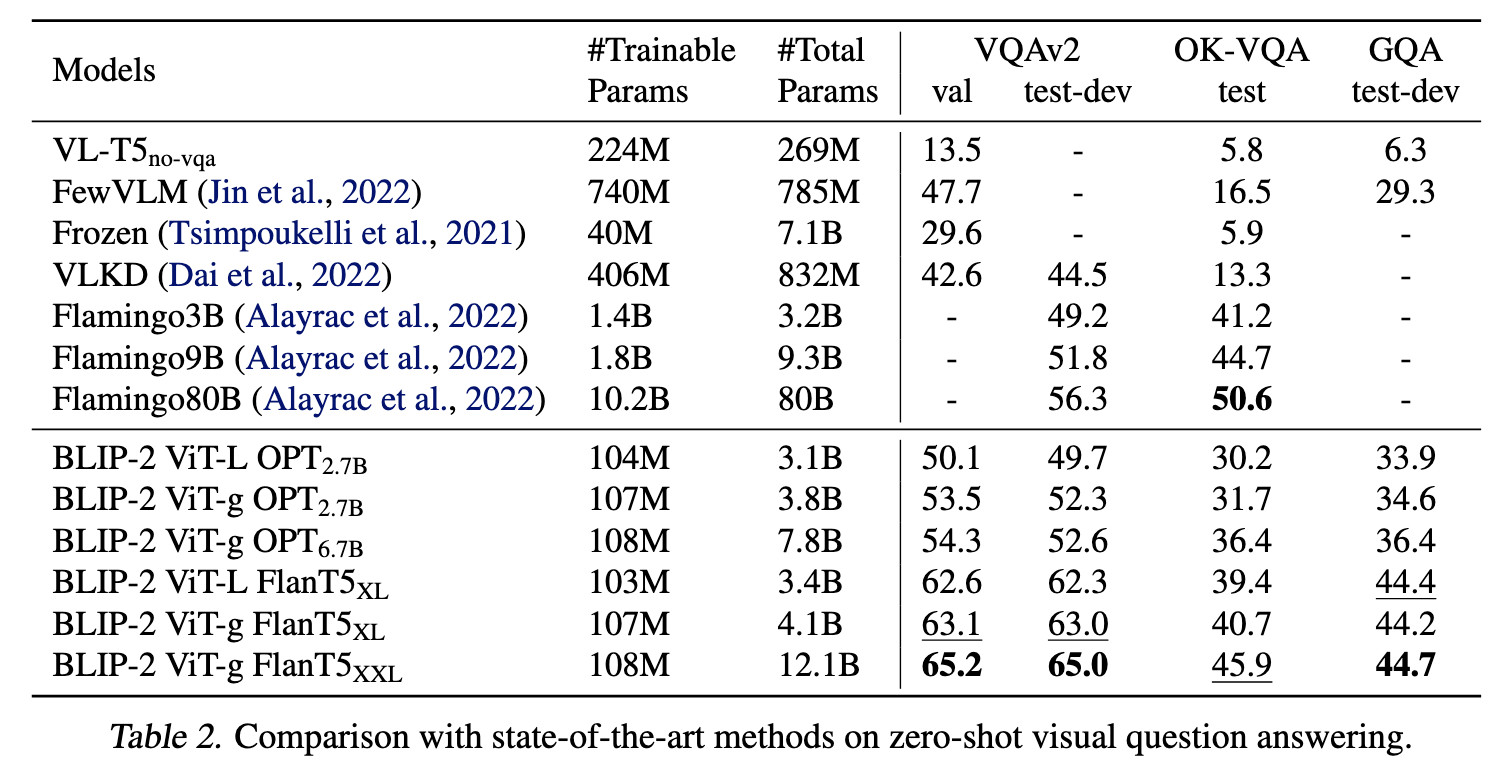
Experiments
- 在各个视觉-语言任务上的zero-shot能力
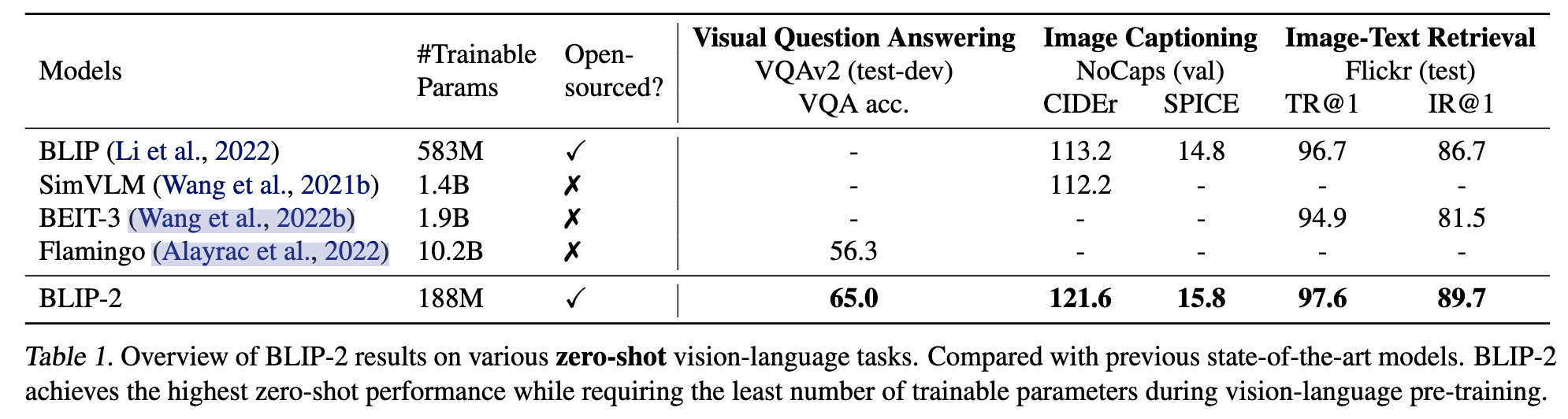
- zero-shot VQA