- Title: BLIP: 引导语言-图像预训练,用于统一的视觉-语言理解和生成
- 作者: Junnan Li Dongxu Li Caiming Xiong Steven Hoi;Salesforce Research
- 发表日期:2022.2
- github: https://github.com/salesforce/BLIP
该论文试图解决什么问题?
目前已经存在的VLP(Vision-Language Pre-training)模型仅仅在理解类任务(understanding-based tasks)或者生成类任务(generation-based tasks)其中一方面表现优秀。 本文主要解决问题有二。
- 提出BLIP,一个新的可以灵活迁移到理解类任务和生成类任务的VLP架构。
- (CapFilt): 网络爬取的数据有噪声,该方法可以提升数据的质量。
Key Contributions
- 提出MED(ultimodal mixture of Encoder-Decoder)架构: 可以有效的多任务预训练和迁移学习。 通过三个视觉-语言目标函数实现:imagetext contrastive learning, image-text matching, and imageconditioned language modeling.
- 提出CapFilt(Captioning and Filtering)方法: 从有噪声的数据训练。captioner模块:输入网络爬取的图片,输出合成的文本描述(caption 任务), filter模块:从合成的图像文本对中删除质量差的数据(noisy captions).
Method
模型结构
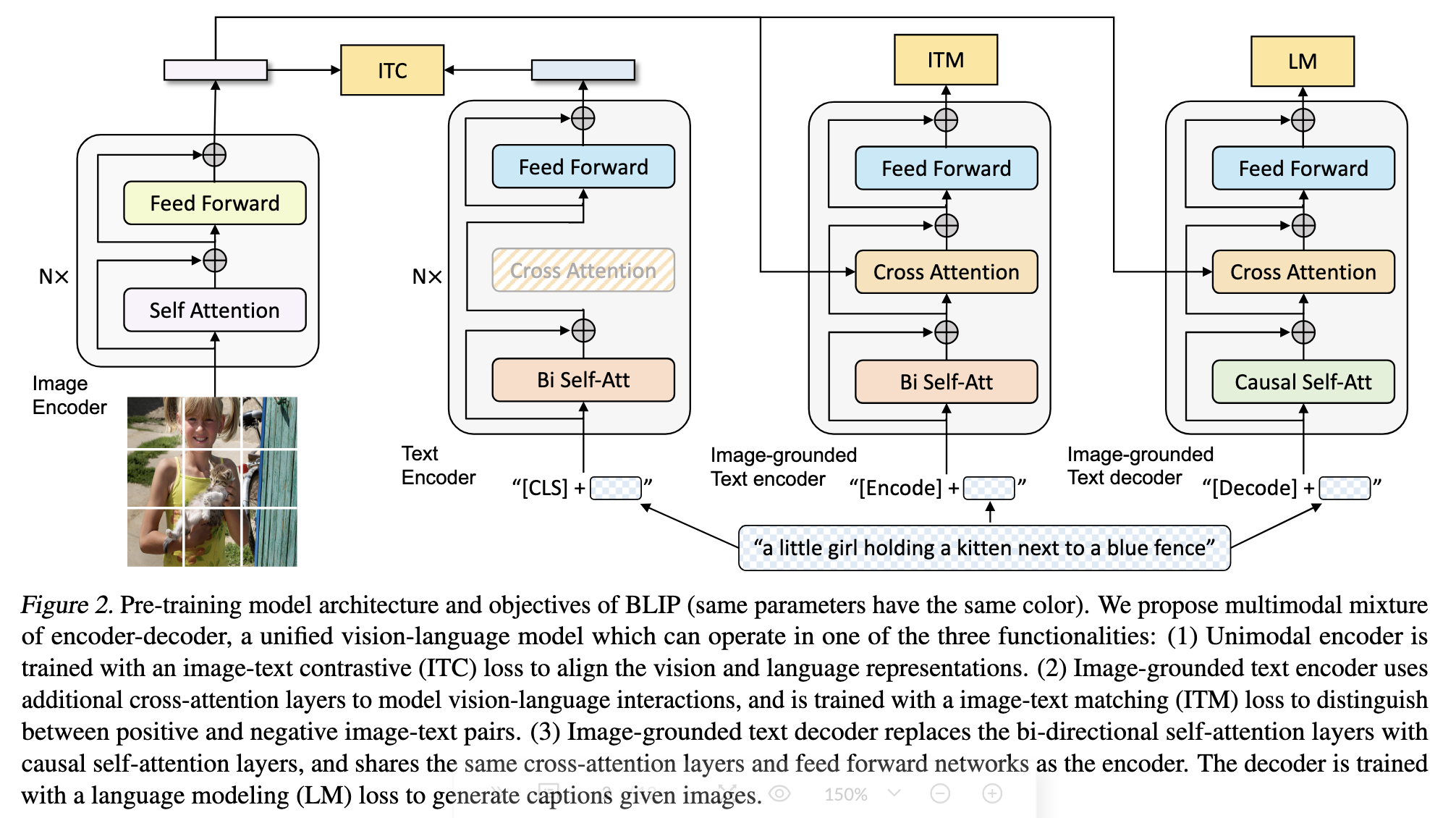
note: 颜色相同的模块共享参数
主要分为三个模块
- Unimodal encoder: 单模态的encoder, 包括图像encoder, 文本encoder
- Image-grounded text encoder: 通过cross-attention进入视觉信息
- Image-grounded text decoder: 用于生成任务
预训练目标函数
- Image-Text Contrastive Loss (ITC) 作用:视觉特征空间与文本特征空间对齐(CLIP思想) 实现方式:同一个batch中配对的图像和文本是正样本,不配置的图像和文本是负样本(自已构建正负样本对)。计算cos距离后正样本打高分,负样本打低分。
- Image-Text Matching Loss (ITM) 作用:捕获更细粒度的图像文本对齐特征 实现方式:网络最后接一个全连接层做一个二分类任务。note:与ITC不同
- Language Modeling Loss (LM) 作用:给定图片生成描述 实现方式:交叉熵
CapFilt
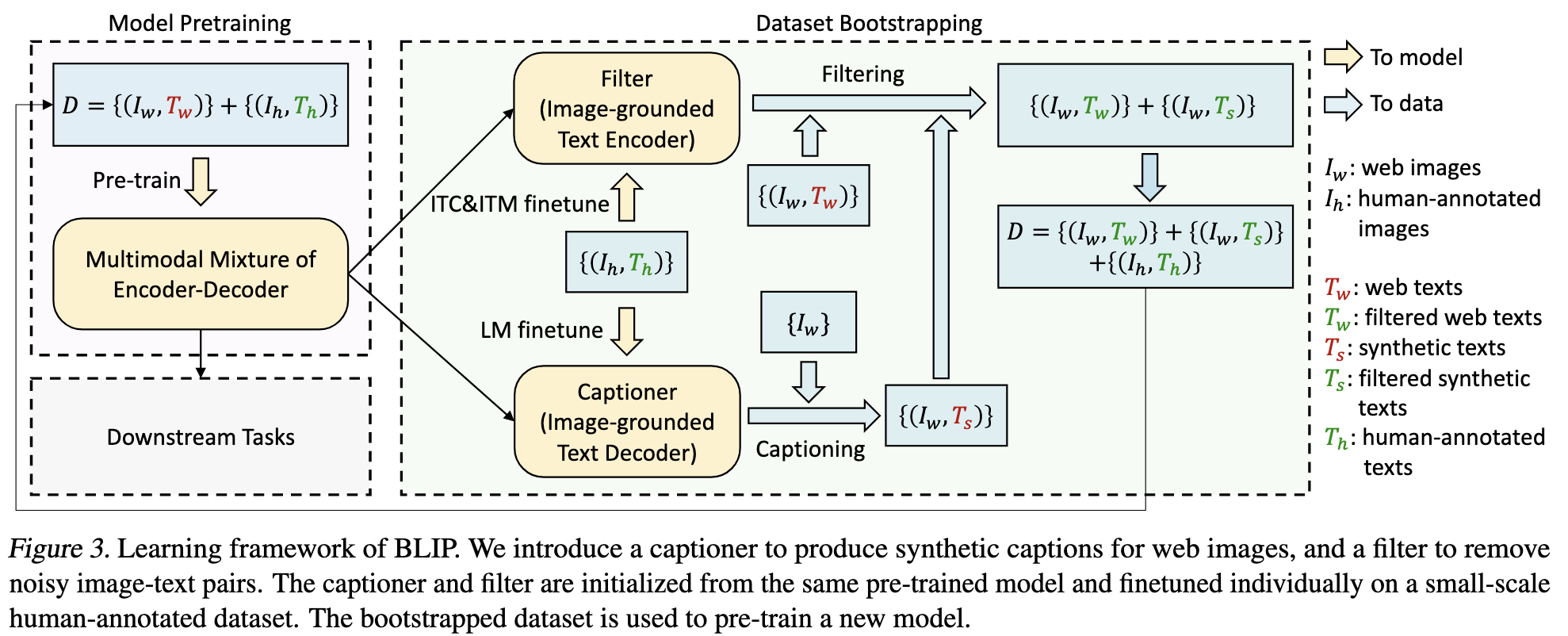
先用网络爬取的数据和人类标注的数据集预训练模型。然后各自(指参数不共享)的finetune captioner模块和filter模块。
captioner: 使用LM目标函数
filter: 使用ITC和ITM目标函数
finetune使用的是coco数据集
Experiments
CapFilt相关的实验
captioner和filter一起使用效果更好
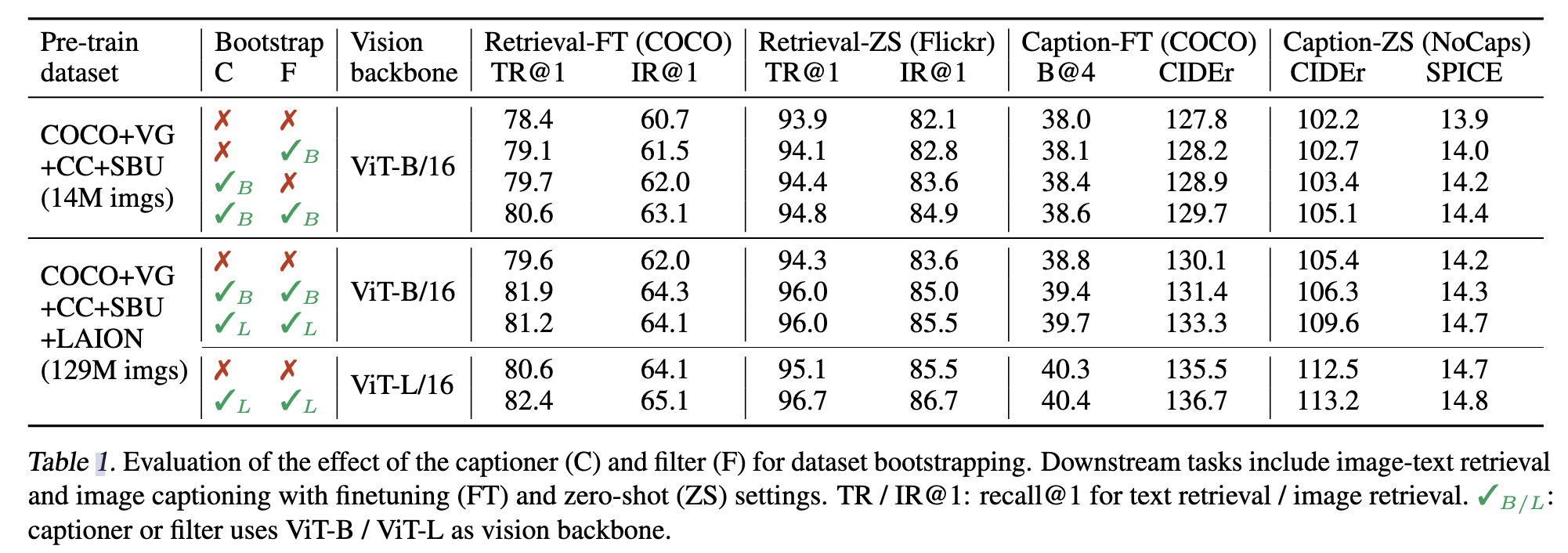
合成的caption生成有两个方式,两个方式比较

a. Beam: 生成的过程中每次选择概率最大的词 b. Nucleus: 搞一个集合,集合中的词概率加起来大于一个阈值(本论文取0.9),然后从集合随机的选取词改实验表明:对于合成的caption,多样性是关键
captioner和filter参数是否共享

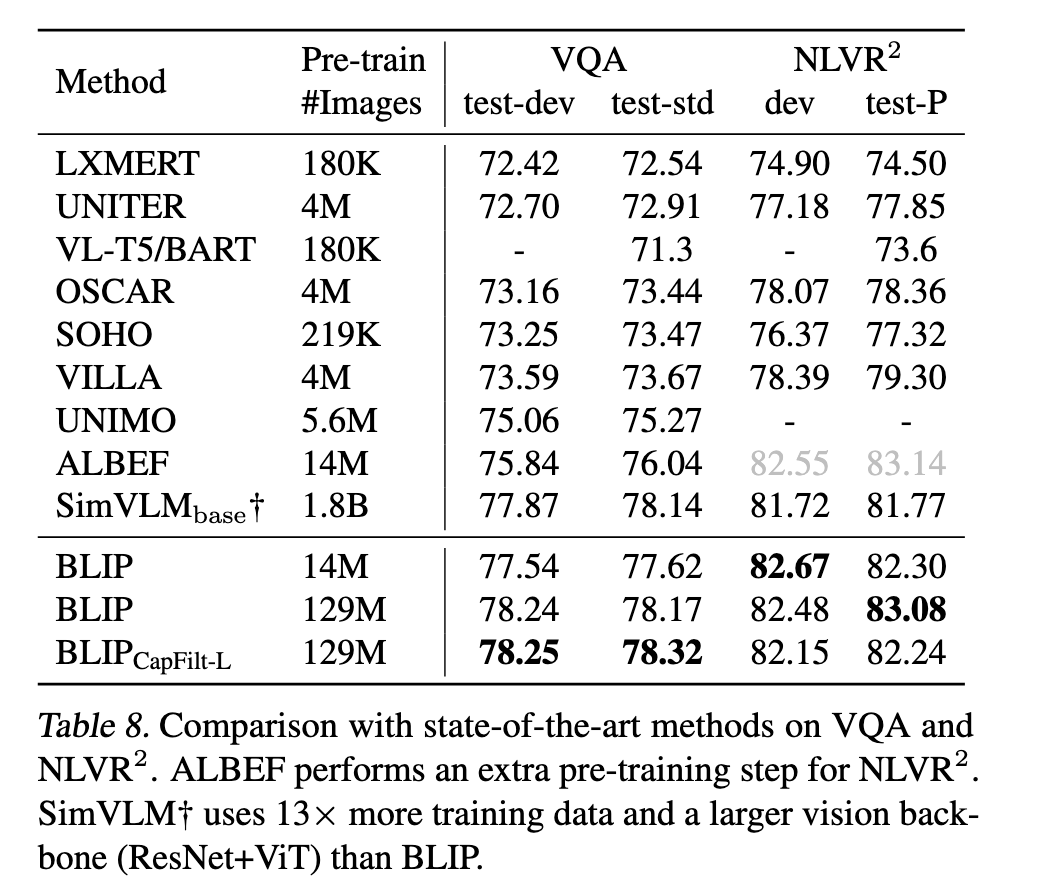
与SOTA模型比较
- 图像-文本召回
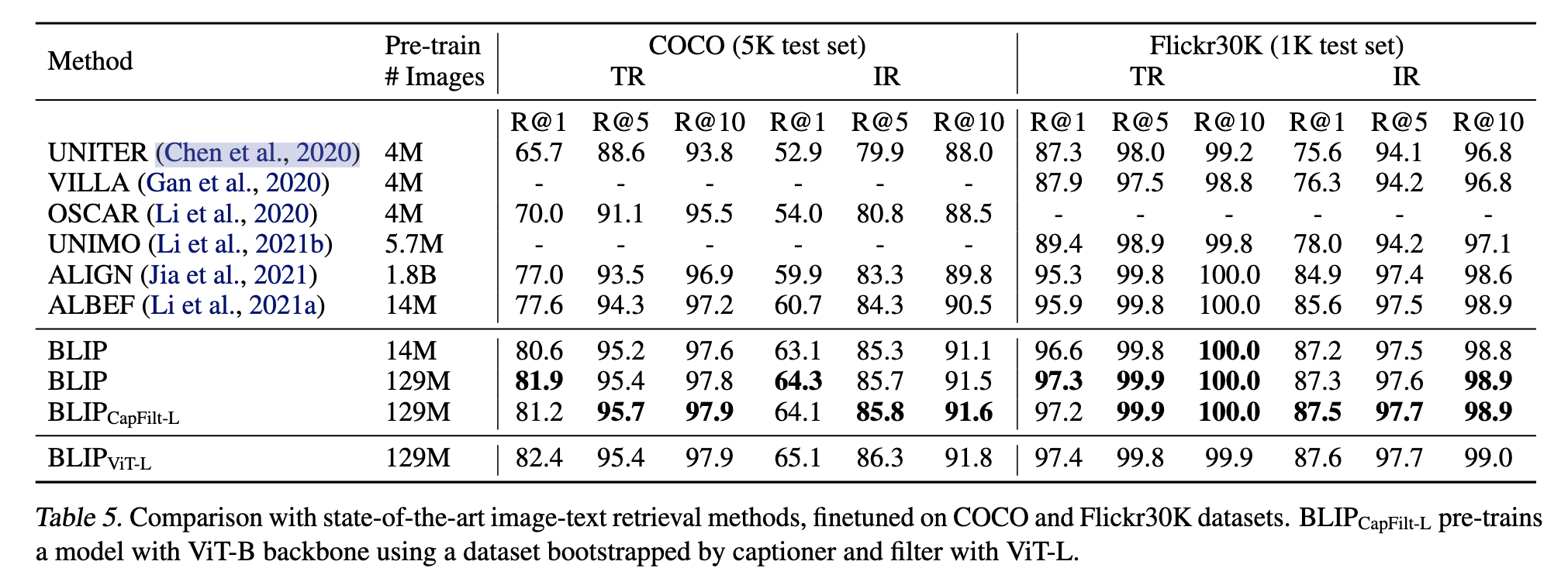
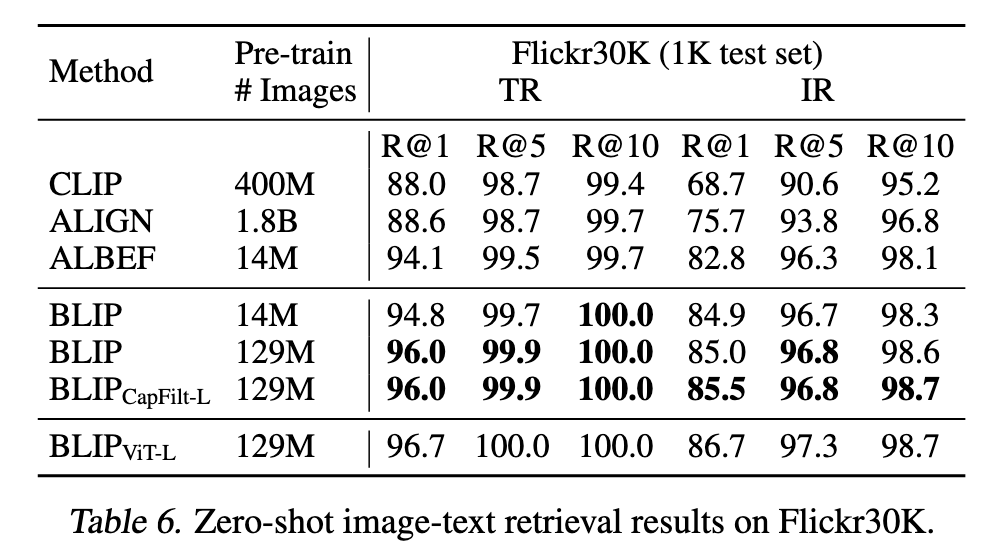
- zero-shot 图像-文本召回
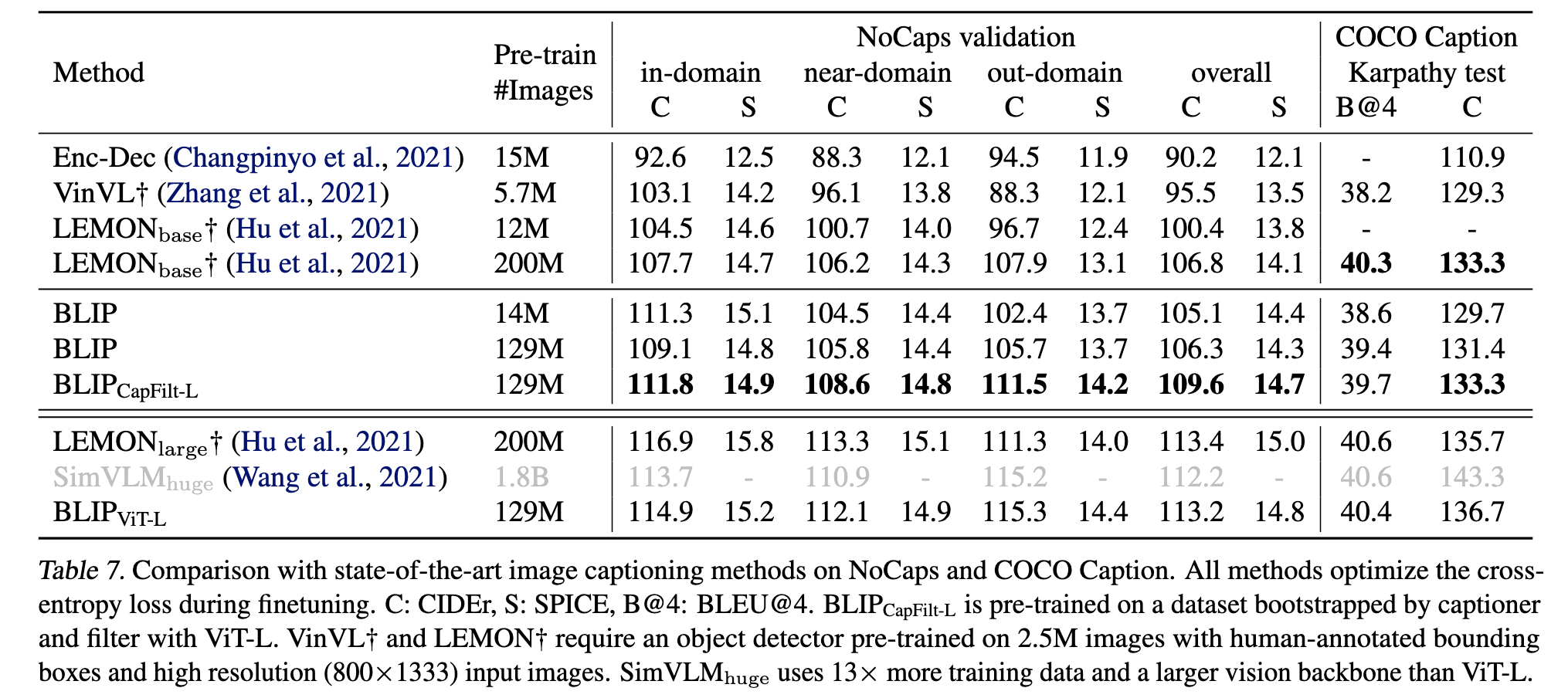
- caption
 优于clip
优于clip - VQA