- Title: 从图像的联合-embedding预测架构中自监督学习
- 作者: Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski1Pascal Vincent, Michael Rabbat, Yann LeCun, Nicolas Ballas
- 发表日期:2023.4
一、Introduction
1.1 该论文试图解决什么问题?
不依赖于手工的数据增强,I-JEPA可以学习到更高阶的语义图像特征。同时I-JEPA还具有可伸缩性、计算高效等优点。
1.2 以往方法存在的问题
Invariance-based methods
- 基本思想:同一张图片的不同视角(不同数据增强方式)的embedding是相似的。
- 缺点:引入很强的偏置(biases),对下游任务有害、甚至对不同分布的预训练任务也有害。
- 优点:学习高层的语义信息
generative methods
- 基本思想:删除图像的一部分,然后预测缺失的部分。
- 缺点:效果差于Invariance-based的方法,且获得底层的语义信息。
Key Contributions
- I-JEPA 学习强大的开箱即用(off-the-shelf)的特征表示,不需要手工的view augmentations。并且由于MAE,半监督等方法
- 在low-level视觉任务,像目标统计、深度估计,I-JEPA也取得了更好性能
- I_JEPA是可伸缩(模型越大,效果越好)且高效(计算高效)的,体现在需要更少的GPU hours,比iBOT快2.5倍,10倍的高效与MAE。
背景知识
常规的自监督范式可以归为以下三类。自监督基本思想都是一样的,incompatible inputs(负样本对)的损失大(high energy), compatible inputs 损失小(low energy)
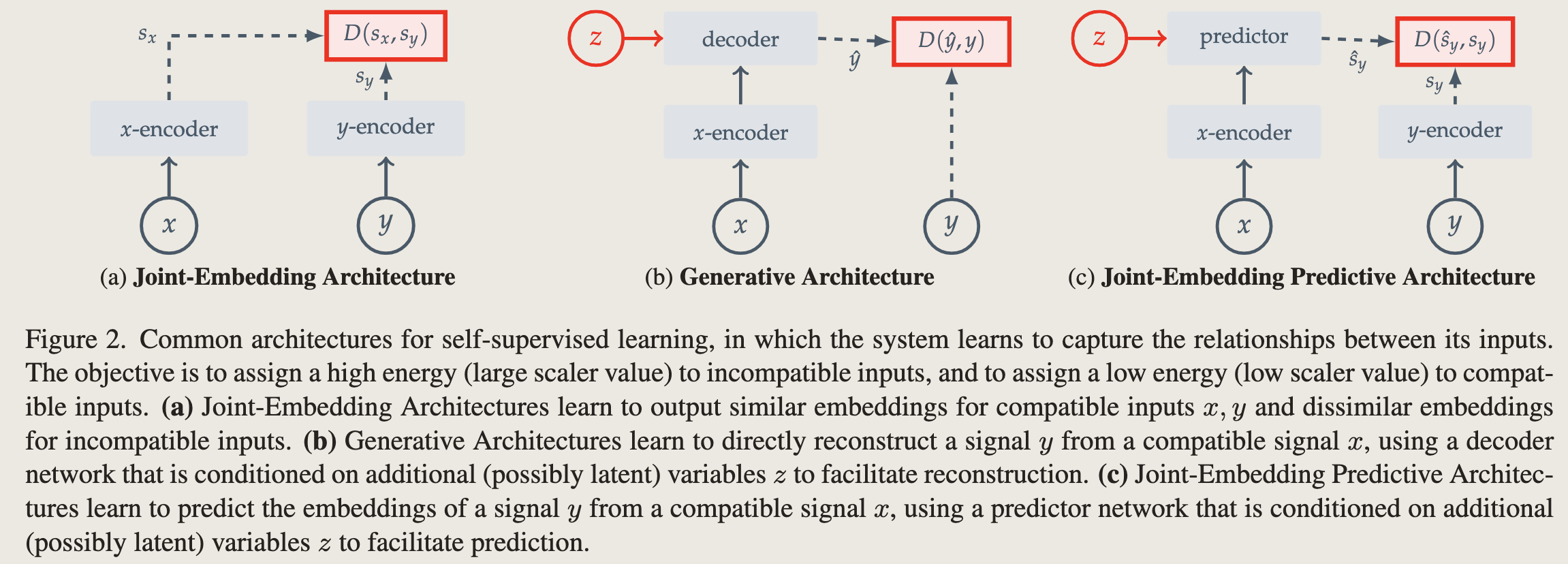
- Joint-Embedding Architectures: 正样本对encoder后,特征是相似的(打高分),负样本对,特征不相似(打低分)
- Generative Architecture: 直接从一个隐变量中重构,类似于VAE
- Joint-Embedding Predictive Architectures: 与Joint-Embedding Architectures类似,只不过对比损失的是两个embedding
Method
核心思想如下图所示:
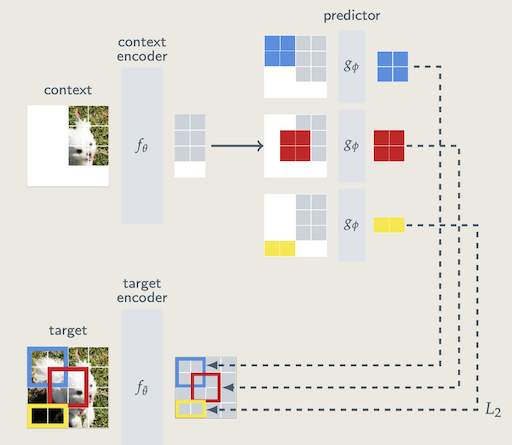 阐述:从一张图片随机采样M(论文中M=4)个区域, 这些区域的长宽比在(0.75, 1.5)之间,然后随机缩放,缩放比在(0.15, 0.2)之间。然后这M个区域经过target encoder,得到特征表示。这些特征表示就是需要预测的东西(与直接预测像素不同)。context经过context encoder,然后加上位置编码去预测target网络得到的特征。该图画的有点问题,context encoder和target encoder的输入图片应该是没有交集的,这个论文其它部分有说。采用的损失是$L_2$损失
阐述:从一张图片随机采样M(论文中M=4)个区域, 这些区域的长宽比在(0.75, 1.5)之间,然后随机缩放,缩放比在(0.15, 0.2)之间。然后这M个区域经过target encoder,得到特征表示。这些特征表示就是需要预测的东西(与直接预测像素不同)。context经过context encoder,然后加上位置编码去预测target网络得到的特征。该图画的有点问题,context encoder和target encoder的输入图片应该是没有交集的,这个论文其它部分有说。采用的损失是$L_2$损失
content与tagets的采样例子,可以看出是没有交集的

Experiments
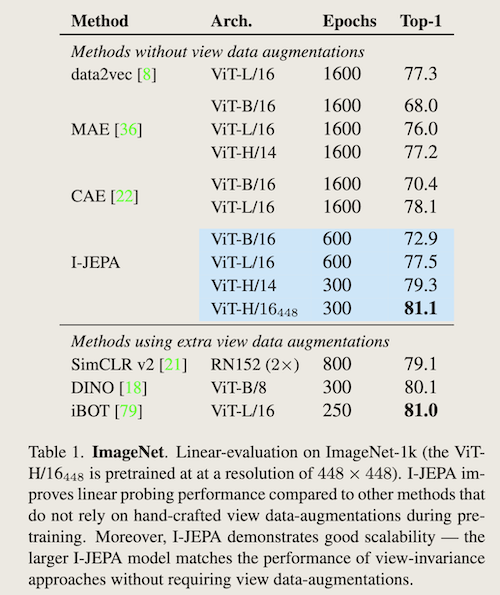
- 在ImageNet-1k分类任务上与其他自监督方法的对比
- 只使用ImageNet数据集中的1%数据半监督学习

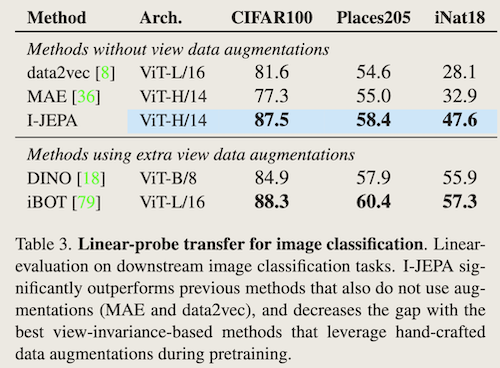
- 迁移学习
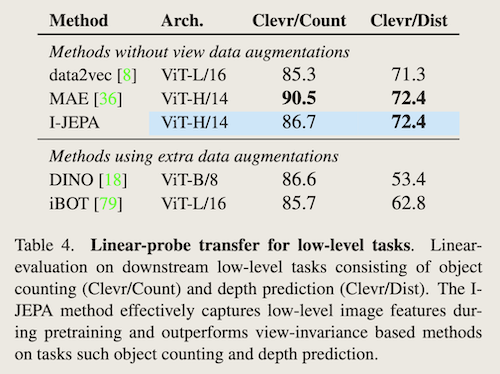
- 在low-level任务上的表现,目标数量统计与深度估计
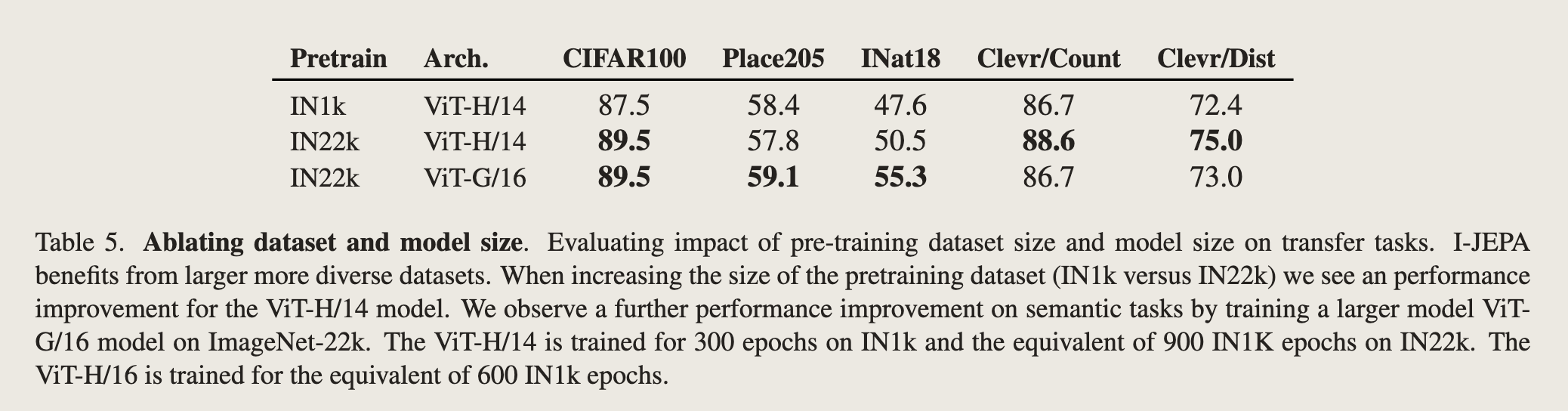
- 方法可伸缩性
- 可视化predictor representations

- tagets的mask策略对比
