- Title: OverNet: 面向开放集目标属性识别
- 作者: Keyan Chen, Xiaolong Jiang, Yao Hu, Xu Tang, Yan Gao, Jianqi Chen, Weidi Xie; Beihang University, Xiaohongshu Inc, Shanghai Jiao Tong University
- 发表日期:2023.3
一、Introduction
1.1 该论文试图解决什么问题?
在开放词汇(open-vocabulary)场景下,同时检测目标和属性。 之前的一些方法是假设bounding box或者分割mask给定,甚至目标类别给定的前提下去做属性的识别的
1.2 Key Contributions
- 提出CLIP-Attr: 两阶段方法,用于开放集的目标检测和属性识别。第一阶段用RPN网络去定位候选目标位置,第二阶段识别目标类别和属性
- finetune CLIP: 为了进一步提升属性和视觉表征对齐的能力。利用图像-文本对进行弱监督训练。
- 提出OvarNet框架:为了提升速度,蒸馏出一个类似于Faster-RCNN类型的端到端模型。
Method
整体结构如下
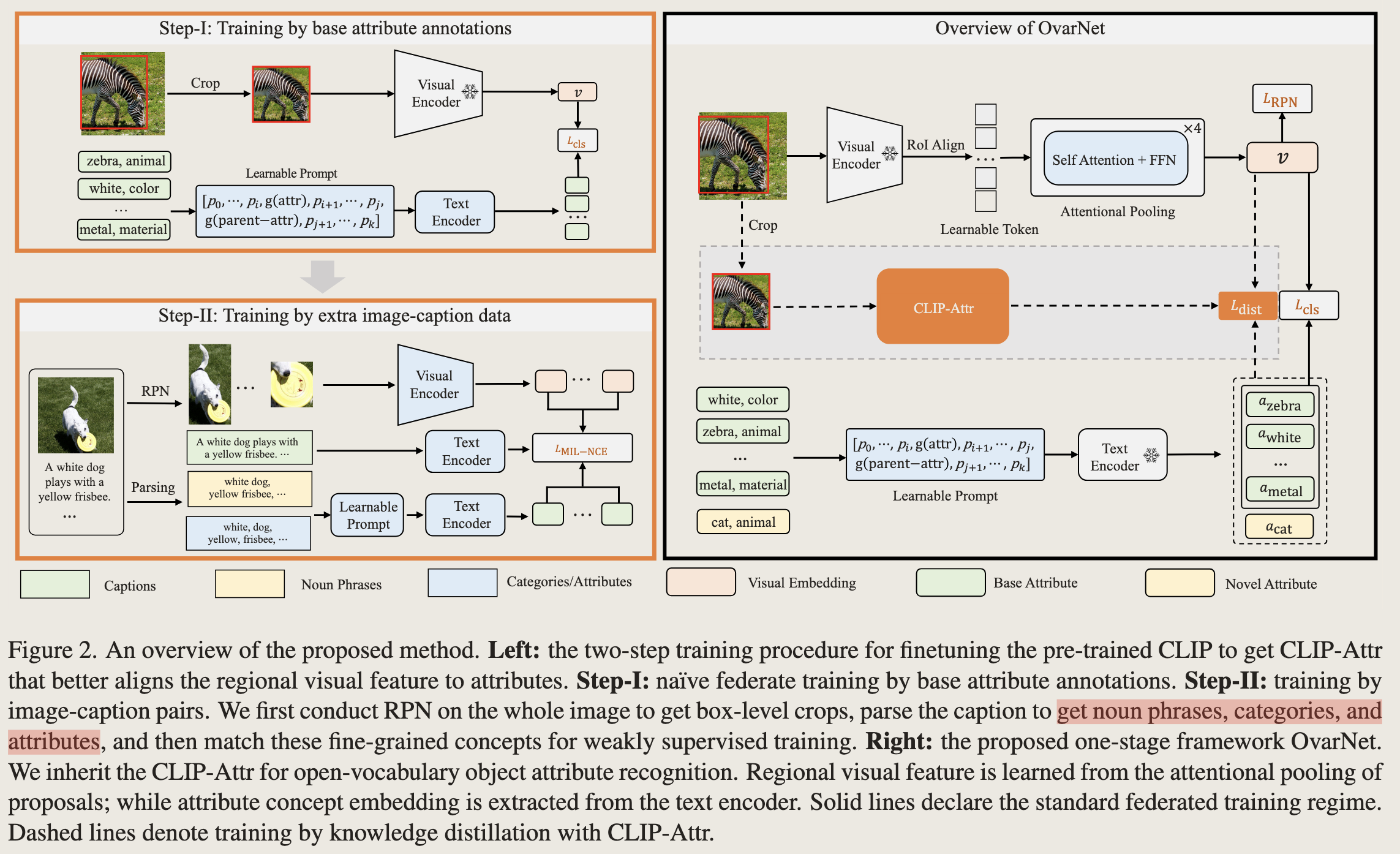
整体结构分为两个部分,左边:CLIP-Attr, 右边:OvarNet
CLIP-Attr 一阶段(visual encoder 冻住, 训练text encoder):
- visual 分支:训练一个RPN网络(用coco数据集训练FasterRCNN的一阶段)用于从图片中定位目标(不需要知道类别)位置。然后输入CLIP的Visual Encoder(该部分参数是冻住的)获取每一个crop的visual representation;
- text分支:将类别和其父类别作为标签,然后标签的前中后分别插入10个可学习的token向量(以往的方式是hard prompt方式,比如“a photo of [zebra]”这种,作者后面有做消融实验,证明该种方式更好)。
- 损失:普通的BCE loss, 这里使用的训练数据是coco attribute prediction dataset 和 VAW。类别数量是固定的,此处还不是open vocabulary。
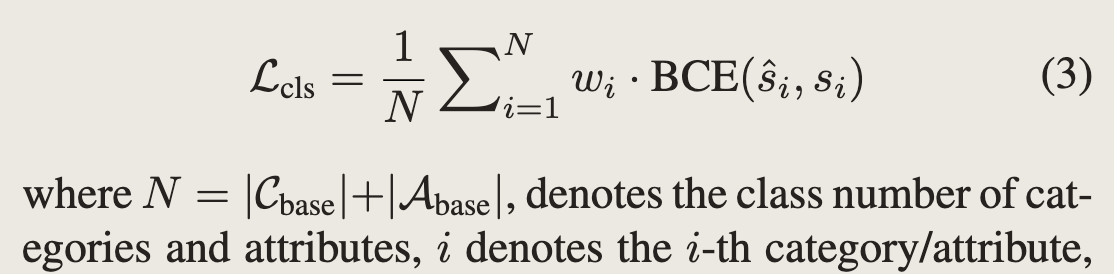
CLIP-Attr 二阶段(visual encoder, text encoder都训练): 一阶段训练得到的模型已经具有一定的能力可以将视觉表征和文本表征对齐,但是还不够且不是open vocabulary的。所以二阶段使用图像-文本对进行弱监督的对比学习。使用TextBlob将captions解析为名词短语(noun phrases)和各种属性(类别也可看着属性)。使用的损失为MIL-NCE(multi instance noise contrastive loss)。
OvarNet(visual encoder, text encoder都冻住,训练RoL Align): 由于每一个crop都需要过visual encoder去获得表征,这一步比较耗时,所以这一步通过蒸馏的方式简化该步骤,可以直接获取每一个crop对应的表征。其余部分也CLIP-Attr类似。损失为 $$L_{total} = L_{cls}+\lambda *L_{RPN}+L_{dist}$$, 其中 $$L_{dist}(\hat{s}, s)=\frac{1}{N}\sum_{i=1}^N KL(\hat{s}, s)$$
Experiments
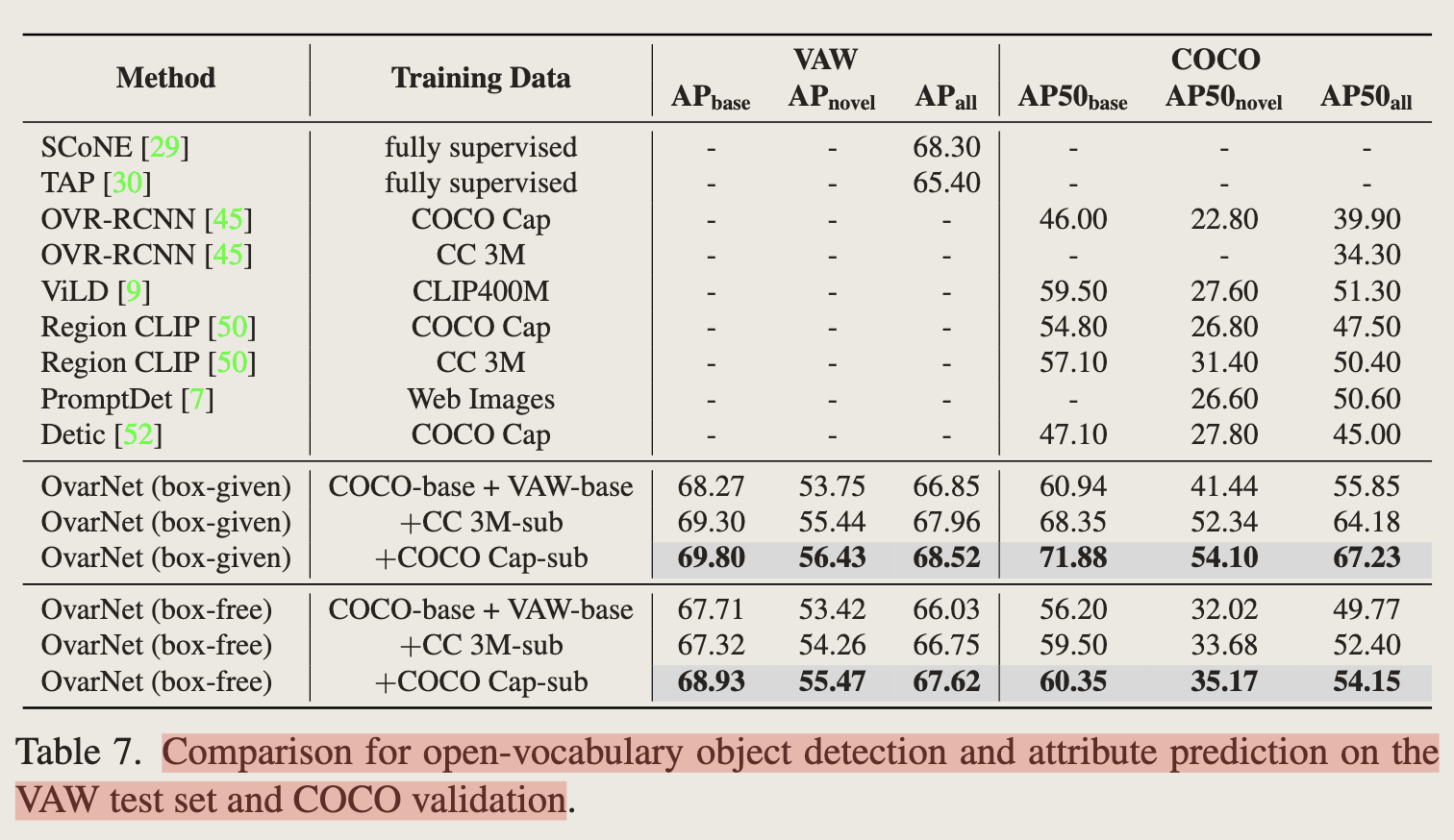
- 在coco和VAW上的结果