- Title: MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
- 作者: Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin1Zhenyu Qiu, Wei Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, Rongrong Ji; Tencent Youtu Lab , Xiamen University
- 发表日期: 2023.7
- 项目主页:MME
Note: 项目主页加入了新的多模模型,得分已经远远超过论文的那个几个模型
一、Introduction
缩写
- LLM: Large Language Model
- MLLM: Multimodal Large Language Model
LLM 三个代表性的能力: In-Context Learning(ICL), instruction following, Chain-of-Thought (CoT)
1.1 该论文试图解决什么问题?
多模模型缺乏一个全面的评估benchmark,该论文首次提出多模大模型的评估benchmark MME。在14个子任务上度量多模大模型的感知和认知能力。
1.2 Key Contributions
- 提出MME多模模型评价指标,首个全面评估MLLM的benchmark。
- 评估12个最新的MLLM在MME的14个子任务上
- 总结暴露的问题,提供MLLM的优化方向
1.3 已经存在的定量评估多模模型的评价方法
- 在传统的多模数据集上评估:比如image caption,VQA。缺点:(1)不能反应多模模型的涌现能力 (2)训练数据集不统一,很难保证所有的多模模型没有在测试集上训练过
- 收集数据开放式评价(open-ended evaluation): 缺点:(1)数据没有开源(2)数据集很小(可能只有50张图片)
- 专注于MMLM的一方面评价:比如object hallucination(幻觉问题),adversarial robustness。 缺点:不够全面
1.4 MME benchmark特点
(1) 覆盖感知和认知能力的评估
感知能力
- coarse-grained(粗粒度)
- existence
- count
- position
- color of objects
- fine-grained(细粒度)
- movie posters: 电影海报
- celebrities: 名人
- scenes: 场景
- landmarks: 地标建筑
- artworks: 艺术品
- coarse-grained(粗粒度)
认知能力
- commonsense reasoning: 常识
- numerical calculation: 算术
- text translation: 翻译
- code reasoning: 推理代码的结果
OCR

(2)所有指令-问答对都是手工构建,对于涉及的少数公共数据集,也只是用图片,没有用标注
(3)MME的指令是很简洁的,从而避免prompt engineering对结果的影响,作者认为好的MLLM有能力泛化到简洁、用户常用的指令
(4)对所有的任务,作者设计的指令要求MMLM回答"yes"or"no", 所以可以很容易的定量评价MLLM
Method
指令设计
为了定量分析,直接设计指令让模型输出yes or no。指令包含两个部分(1)简洁的描述(2)“Please answer yes or no”。 对每张图片设计两个指令。第一个指令的正确回答是yes,第二个指令的正确确实No。 比如图片中两个人。第一个指令设计为“Is there a total of two persion appear in the image?”。第二个指令设计为"Is there only one persion appear in the image?"。第一个指令的回答是yes,第二个为no。这么设计的目的其实是为了检测模型的一致性,如果两个问题MLLM都回答正确,说明模型理解了图片,而不是瞎猜的
评估指标
ACC: 熟知的ACC ACC+: 针对每张图片,两个问题都问题正确(体现模型的一致性)
Experiments
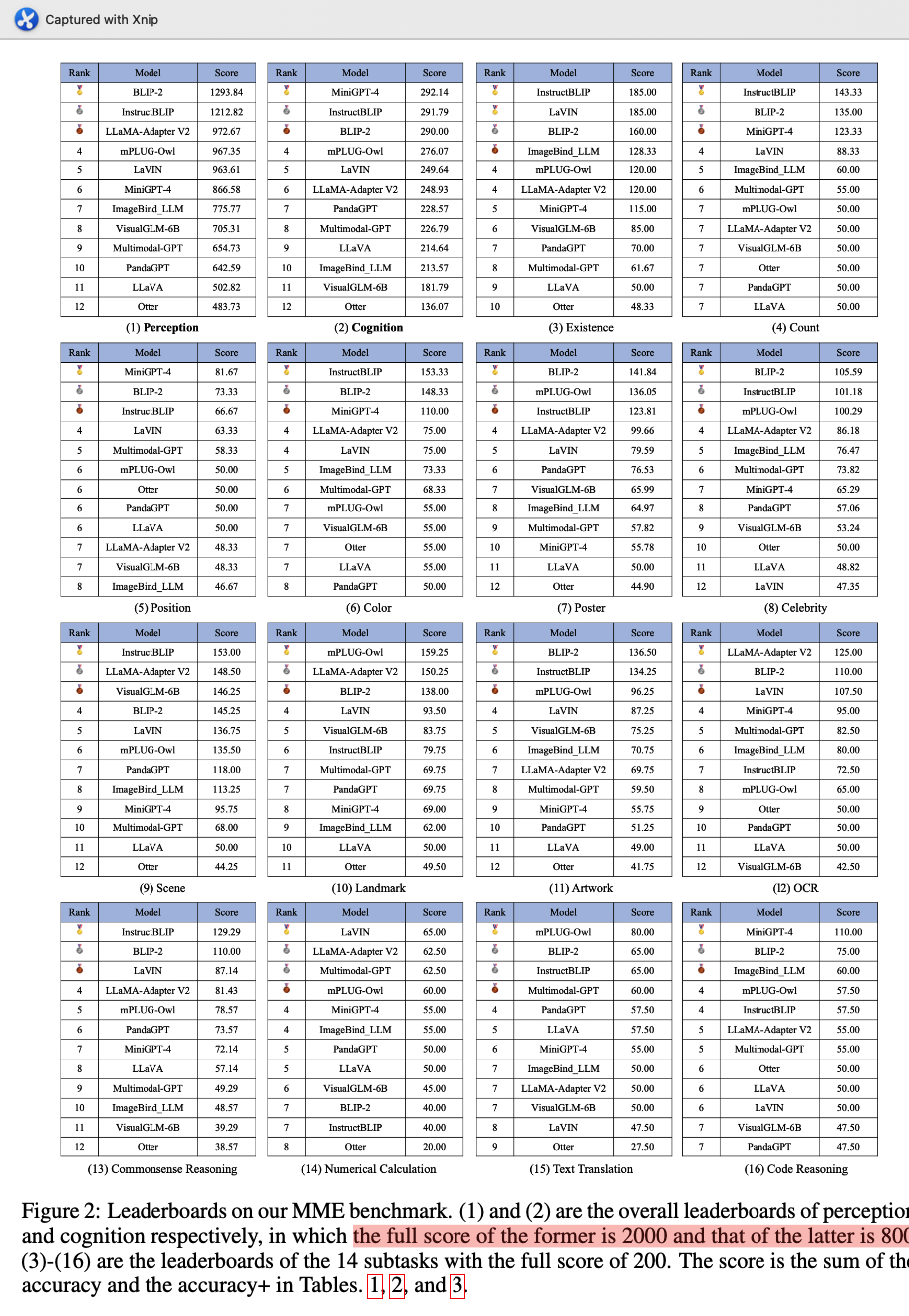
最新的MLLM在MME的评价结果如下,前两个table是分别在感知(总分2000)和认知任务(800)上的总榜,后面14个table是子任务上的得分。总榜的得分是ACC和ACC+两个指标的加权和。
Analysis
影响MLLM性能的4个关键
- 缺乏指令跟随能力
- 缺乏感知能力
- 缺乏推理
- 幻觉