- Title: Flamingo: a Visual Language Model for Few-Shot Learning
- 作者: Jean-Baptiste Alayrac, Jeff Donahue
- 发表日期: 2022.11
一、Introduction
1.1 该论文试图解决什么问题?
多模领域的few-shot问题
1.2 Key Contributions
- 提出Flamingo模型,通过几个示例就可执行各种多模任务。由于架构的创新,Flamingo可以处理随意的图片(可以多张图片)和文本
- 通过few-shot学习,定量评估Flamingo是如何迁移到其他各种任务的
- 通过few-shot学习,Flamingo在16任务中的6个任务(6个人任务是finetune过的)取到SOTA。Flamingo可以在其他数据集上通过fine-tune取到SOTA。
Method
Flamingo架构总览如下图
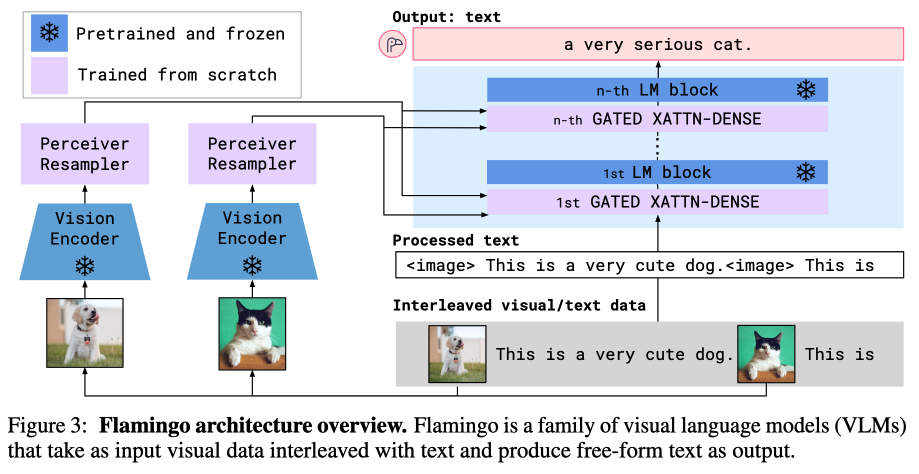 从图中可以看到Flamingo架构有两个关键点组件,Perceiver Resampler和Gated XATTN-DENSE
从图中可以看到Flamingo架构有两个关键点组件,Perceiver Resampler和Gated XATTN-DENSE
- Perceiver Resampler: 任意数量的图片或者视频经过视觉模型编码后,再通过Pereiver Resampler输出固定数量的visual tokens。注:该模块决定了Flamingo可以处理多张图片的能力(即具有few-shot的能力)
- Gated XATTN-DENSE: 主要是指cross attention的基础加入门机制(tanh(a), a初始化为0),可以提升性能和训练的稳定性
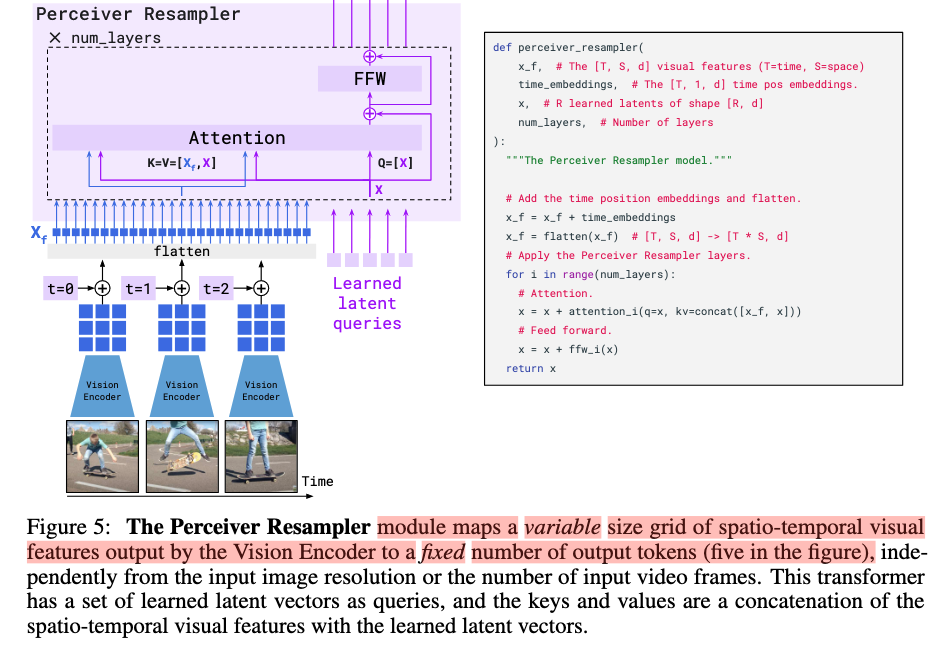
Visual processing and the Perceiver Resampler
Perceiver Resampler示意图如下,学习DETR的query机制,有几个query,输出就是几个visual token(论文中为5)
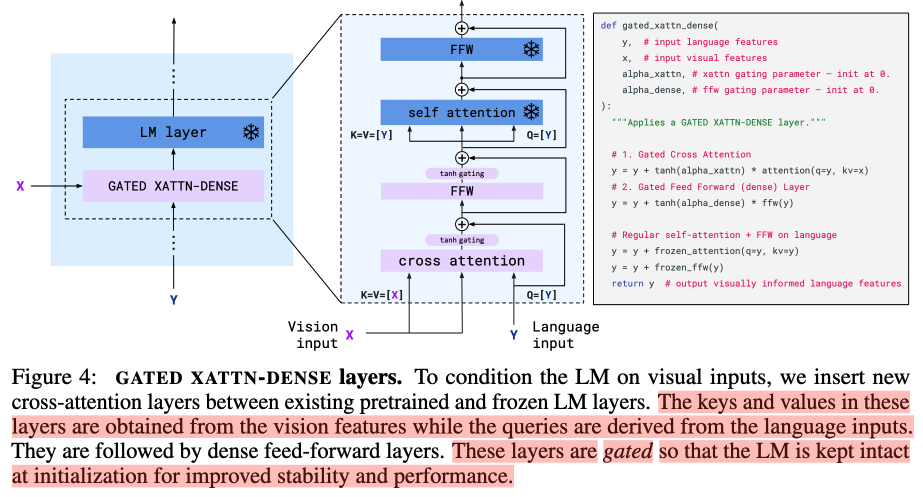
Conditioning frozen language models on visual representations
在Transformer中的cross attention的基础加入门机制
Multi-visual input support: per-image/video attention masking
网络上爬取的文档是图片和文本交错的信息。该模块是用来控制当前文本token可以注意到的图片(离当前文本token最近的上一个图片)

Training on a mixture of vision and language datasets
Flamingo训练采用了三个数据集:
- M3W: Interleaved image and text dataset 4300万,序列长度256(包含5张图片)
- image-text pairs: 18亿ALIGN基础上扩充,3.12亿LTIP
- video-text pairs: 2700万短视频(平均时长22s)
Task adaptation with few-shot in-context learning
通过few-shot迁移到其他任务
Experiments
- 与SOTA模型比较(即包括zero|few shot模型、也包括finetune过的模型)
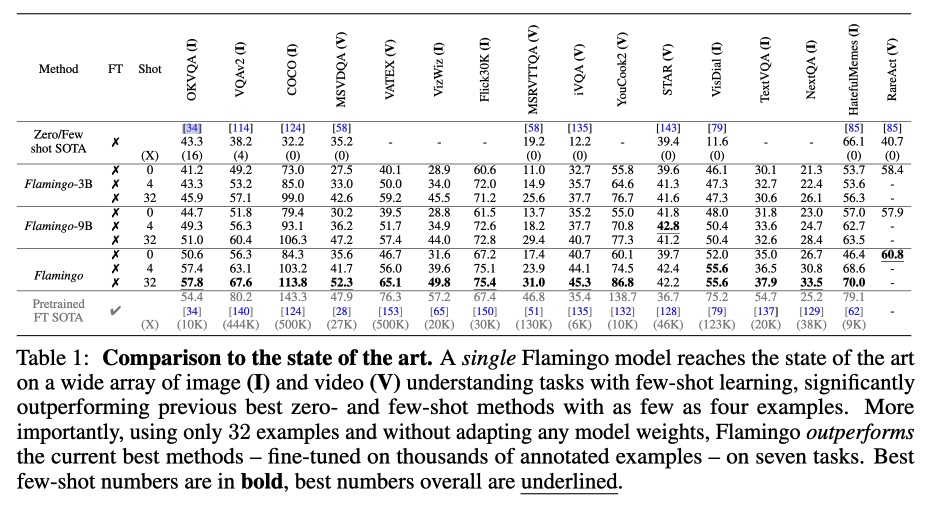 2. Finetune Flamingo(与few shot不如别人finetune的7个任务再次比较)
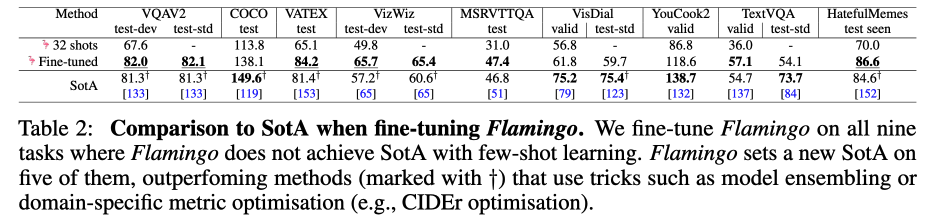
2. Finetune Flamingo(与few shot不如别人finetune的7个任务再次比较)
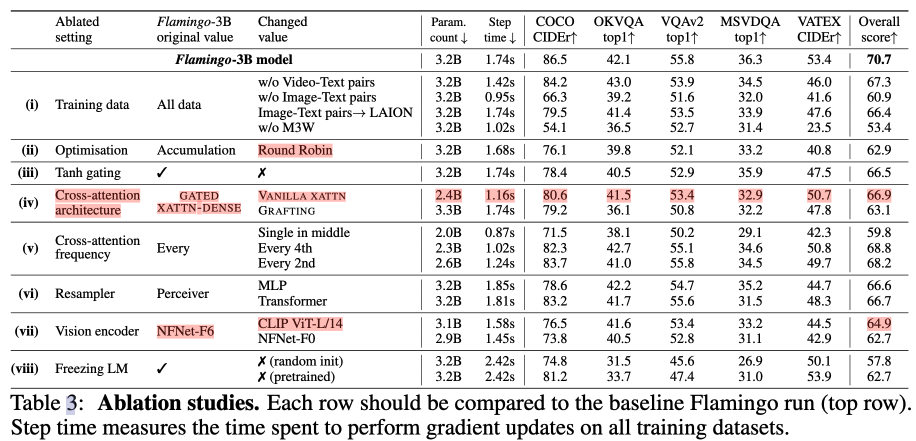
 3. 消融实验
3. 消融实验