- Title: PINK: UNVEILING THE POWER OF REFERENTIAL COMPREHENSION FOR MULTI-MODAL LLMS
- 作者: Shiyu Xuan
- 发表日期: 2023-10-01
一、Introduction
背景知识
- Referring:识别图片中具体的目标类别(包括给定point、bounding box、mask等)
- Grounding:给定文本描述,输出bounding box
简单来讲,Referring是给定坐标,输出文本(类别或者描述);Grounding是给定文本,输出坐标
1.1 该论文试图解决什么问题?
大部分的MLLM缺乏指代能力(Referential Comprehension (RC)),这篇提出一个新方法增强MLLM的RC能力。这篇文章中RC即包括Referring能力也包括Grounding能力
1.2 Key Contributions
- 提出pink增加MLLM的RC能力
- 用设计的各种RC任务,以一个低成本的方式构建质量微调数据集。为了进一步提升模型RC能力,提出自一致提升方法(self-consistent bootstrapping )扩展一个数据集的dense object annotations到高质量的referring-expression-bounding-box pair。
- 端到端训练框架,两个模态从指令微调中都收益(视觉、LLM加入了可学习参数,Adapter)
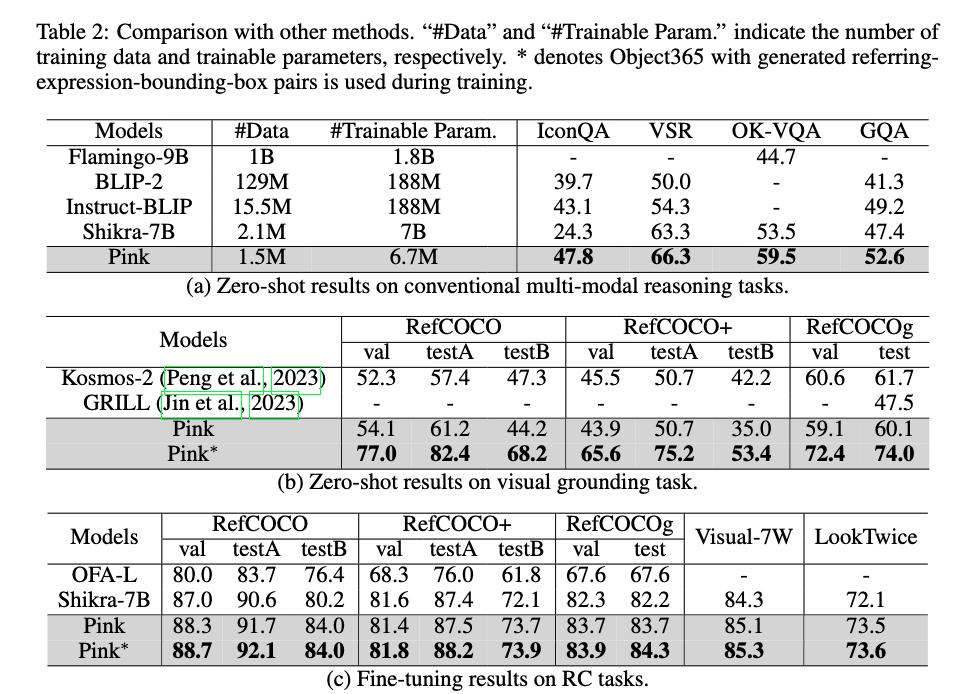
- SOTA(在某些方面比Kosmos-2还强)
介绍中的要点
- 传统VQA和RC的区别
 传统的VQA是image-level的, RC VQA是更细粒度的
传统的VQA是image-level的, RC VQA是更细粒度的
Method
整体架构
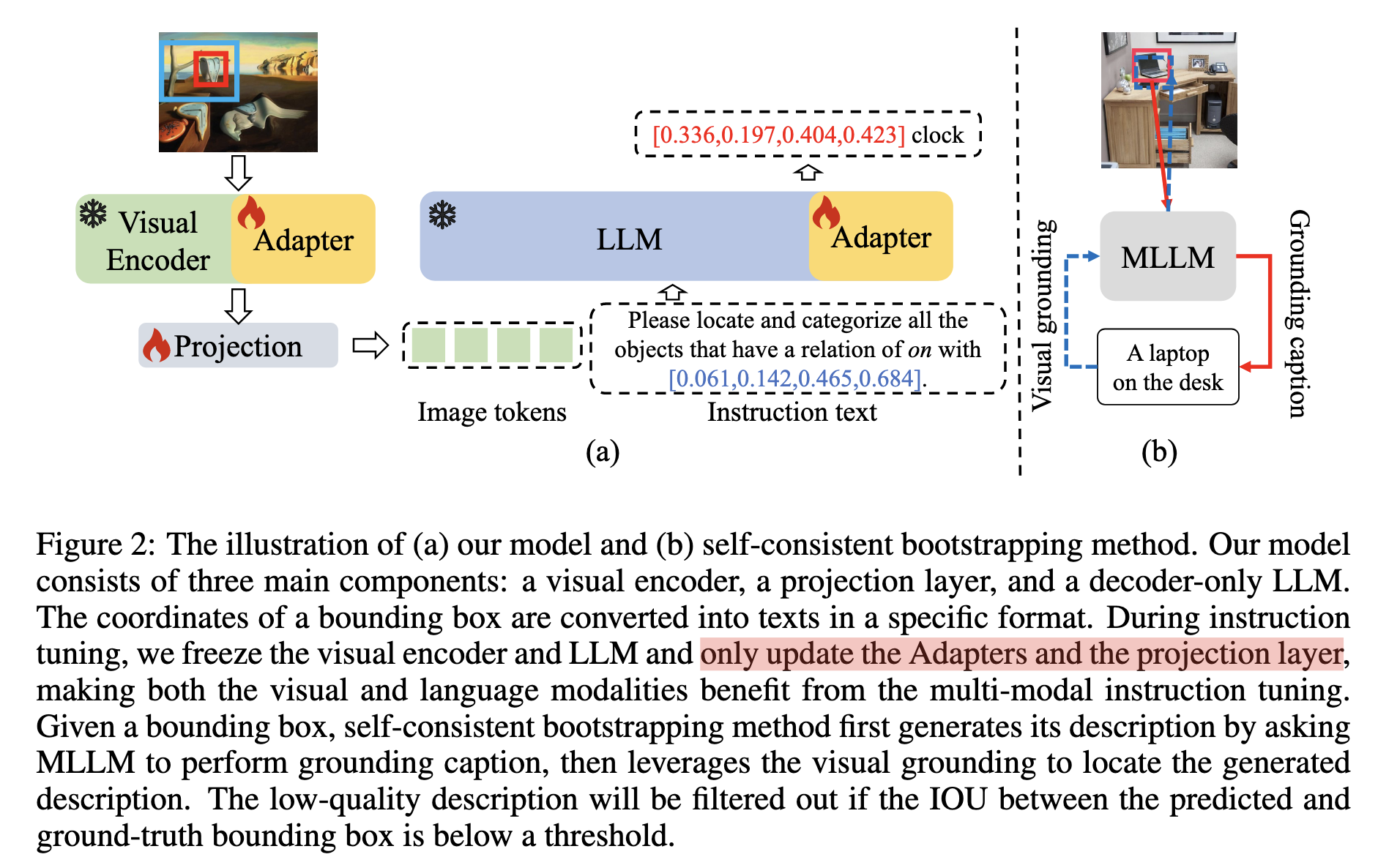 右边的self-consistent bootstrapping包括两步(1)grounding caption: 给定框生成caption,(2)visual grounding: 给定caption预测框
右边的self-consistent bootstrapping包括两步(1)grounding caption: 给定框生成caption,(2)visual grounding: 给定caption预测框
左边的模型结构包括visual encoder,projection layer,decoder-only LLM。
Training Pipeline:(1)第一阶段:只训练projection layer;(2)第二阶段:冻结e visual encoder和LLM。 训练新添加的Adapters参数(viusal encoder和LLM都会新加一些参数)和projection layer
指令微调数据集构建

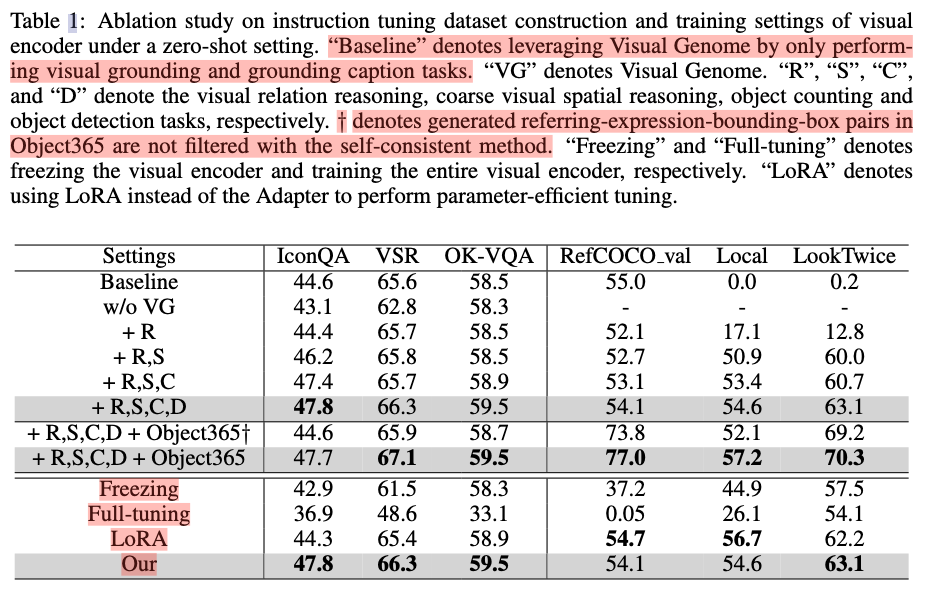
设计的RC task包括如下(前3个是已经存在工作的方法,后面的是作者后设计的)
- visual relation reasoning
- visual spatial reasoning
- PointQA
- Visual Relation Reasoning
- Coarse Visual Spatial Reasoning:define four coarse spatial positions as top-left, top-right, bottom-left, and bottom-right.
- Object Counting
- Object Detection
这些指令模型都是针对VG数据集的

SELF-CONSISTENT BOOTSTRAPPING METHOD
整体架构章节已经说过,该模块主要用于过滤Object365中低质量的数据,最终生成的数据格式为referring-expression-bounding-box对。如下图所示。

Experiments