- Title: Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
- 作者: Mostafa Dehghani
- 发表日期: 2023.7
一、Introduction
1.1 该论文试图解决什么问题?
对于视觉模型而言,resize图片到一个固定的分辨率,不是最优的。ViT具有灵活的序列建模能力,该文利用Vit的这一优势,在训练的时候使用训练打包(sequence packing)去处理任意分辨率和长宽比的图片。在训练效率和最终的效果,都取得了比较好的效果。
注:在卷积网络时代,resize图片或者padding图片到固定大小是标准做法,但是基于Transformer架构的模型,这一做法其实不是必须的。resize图片损害性能,padding损耗效率。
1.2 Key Contributions
Method
preliminary(个人补充,非论文中的信息)
背景:在NLP处理变长序列的做法是将多个样本组合成一个序列,步骤如下(以pytorc中的方法举例):
- pad_sequence:通过pad方式对齐多个序列,使得多个序列长度一样
- pack_padded_sequence:将多个序列打包为一个序列,返回对象PackedSequence
- pad_packed_sequence:将PackedSequence对象解压回来
将pad后的序列(等长的)输入模型计算会浪费计算资源,因为pad也参与计算了。PackedSequence避免这一缺点。
Architectural changes
借鉴NLP中处理思路,将其用在图像上,作者称为Patch n’ Pack操作。
整体思路如下:
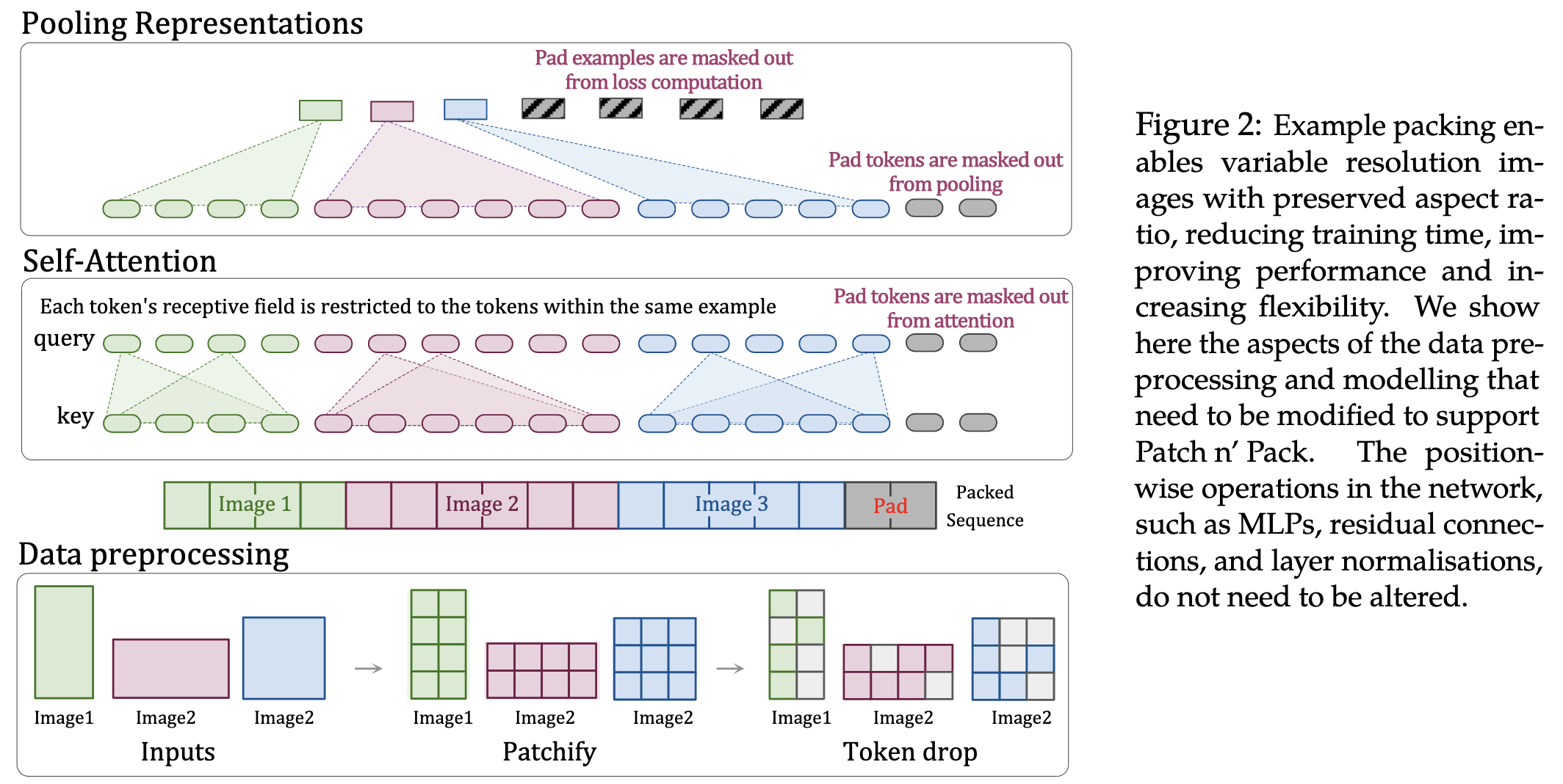
- Masked self attention and masked pooling:使用mask机制,使得每个样本只能注意到自已。
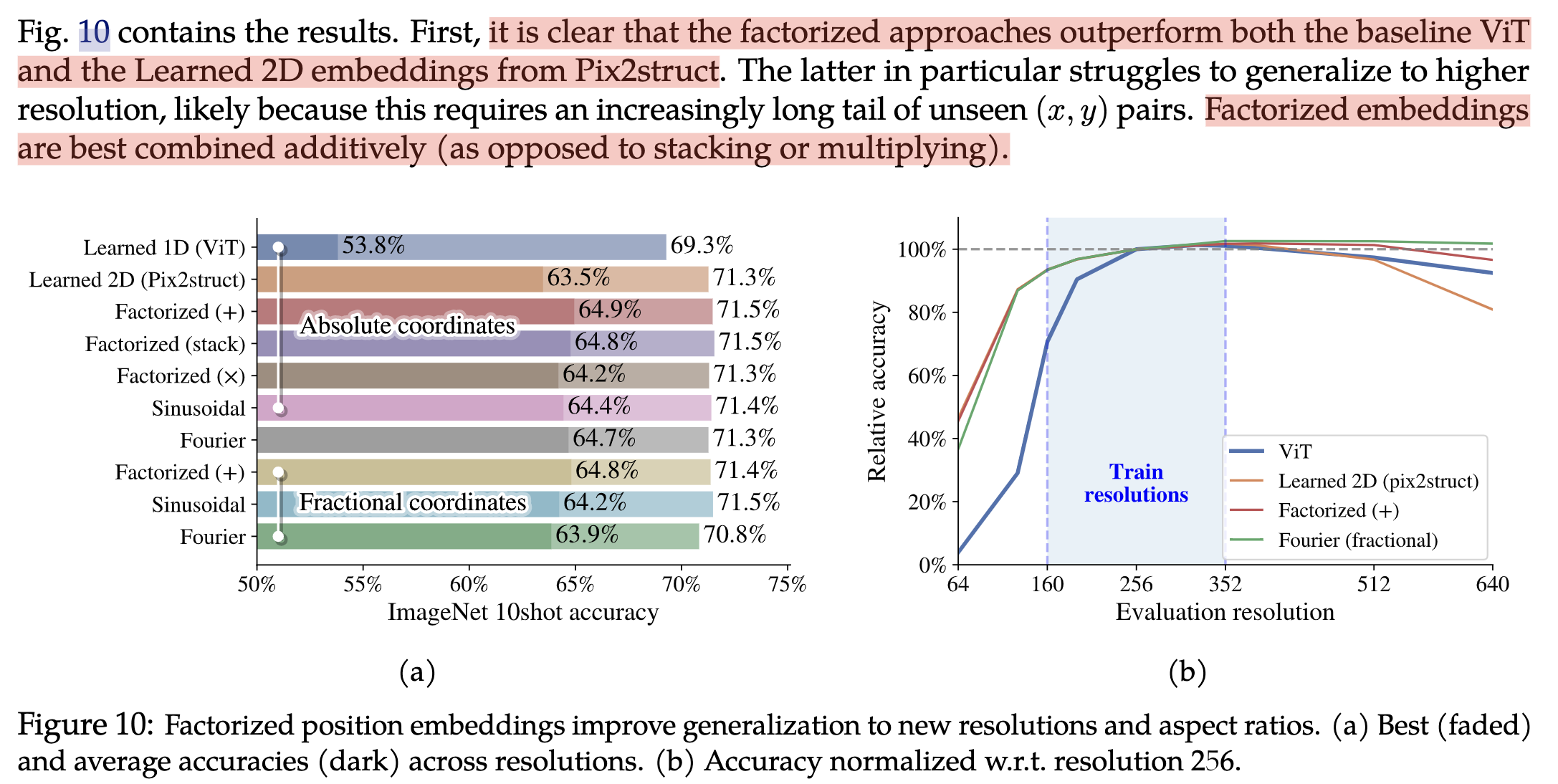
- Factorized & fractional positional embeddings:使用二维位置编码,x,y两个方向独立。使用的时候,可以x,y相加,stack,相乘,论文中实验对比。 这里的说讲位置编码使用小数表示(fractional)没有理解该含义???
Training changes
- Continuous Token dropping:drop连续的token
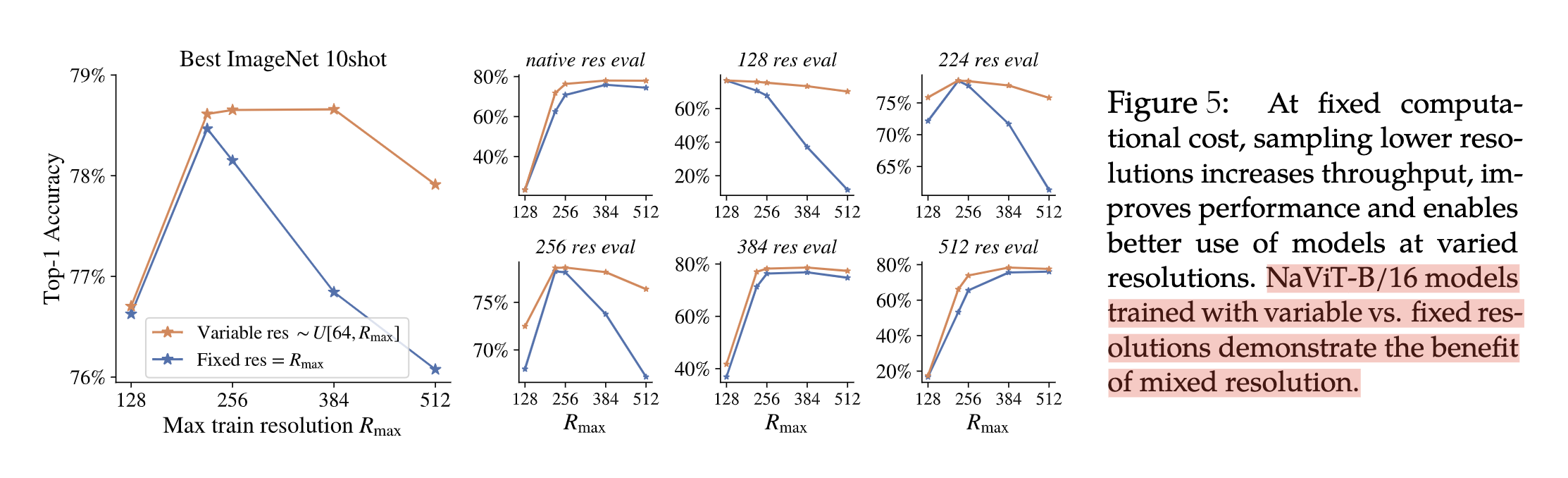
- Resolution sampling:原始的ViT存在一个矛盾点,高吞吐量(在小的图片上训练)和高性能之间(在大的图片上训练)。NaViT在保证长宽比同时做分辨率采样。
Experiments
- 固定分辨率和可变分辨率对结果的影响
- 分解的位置编码由于传统的ViT的位置编码和可学习的2d位置编码(Pix2Struct)
参考资料
- NaVit实现(非官方):https://github.com/kyegomez/NaViT/tree/main