Seed1.5-VL是字节当前最新的具有多模理解和推理的多模大模型方面的工作。Seed1.5-VL由一个532M参数的vision encoder和一个20B激活参数的moe架构LLM组成。在60个公开测试基准中,38项SOTA。
目前来看,最近各大厂发布的多模大模型在模型架构下都大体一致,比如Qwen2.5-VL、InternVL3、Kimi-VL。架构都是vision encoder+LLM+Adapter(MLP), 且视觉特征和文本特征都是通过adapter做一个浅层的融合(早期会有一些工作是深层融合,比如Flamingo、CogVLM等)。vision encoder这个部分Seed1.5-VL、Qwen2.5-VL、Kimi-VL都支持动态分辨率输入。
Seed1.5-VL确实借鉴了大量的当前最新的工作,比如vision encoder借鉴EVA系列的工作(即学习图片的几何结构特征、也学习语义特征);在pre-training阶段使用了大约15亿样本量(粗略估计论文中提到的数据,还不包含没有提到的数据,比如视频用了多少?),把大量不同类型数据提前放到pre-training阶段训练,比如STEM类型数据等;在post-training阶段,使用迭代的方式训练。一个iteration包含cold-start SFT+RL(RLHF+RLVR)。通过RL训练的model收集一些困难样本,通过拒绝采样得到好的答案,这些数据再加上SFT的数据,多次迭代这个过程(seed1.5-VL迭代4次这个过程)。
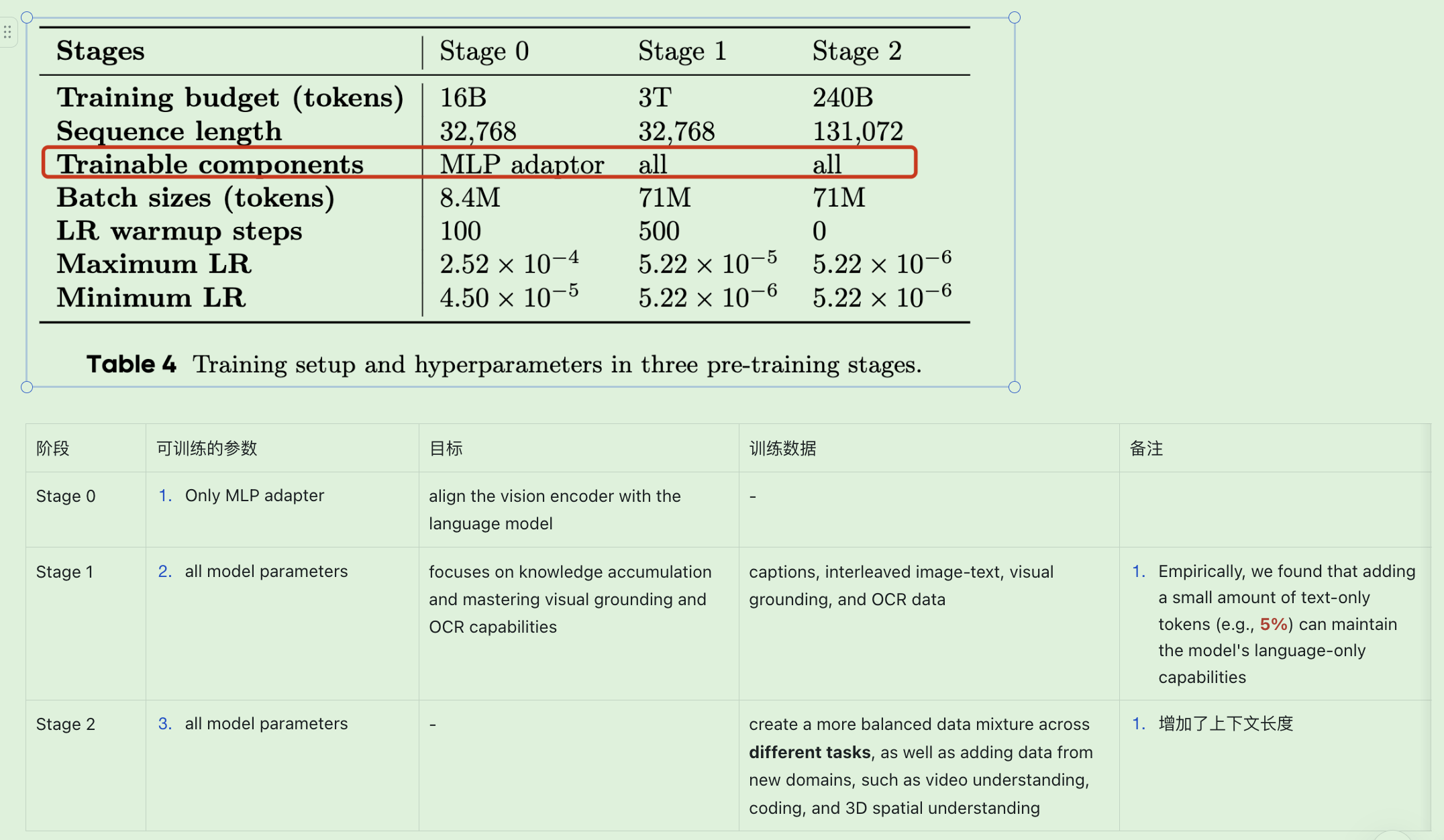
pre-training阶段的setup如下
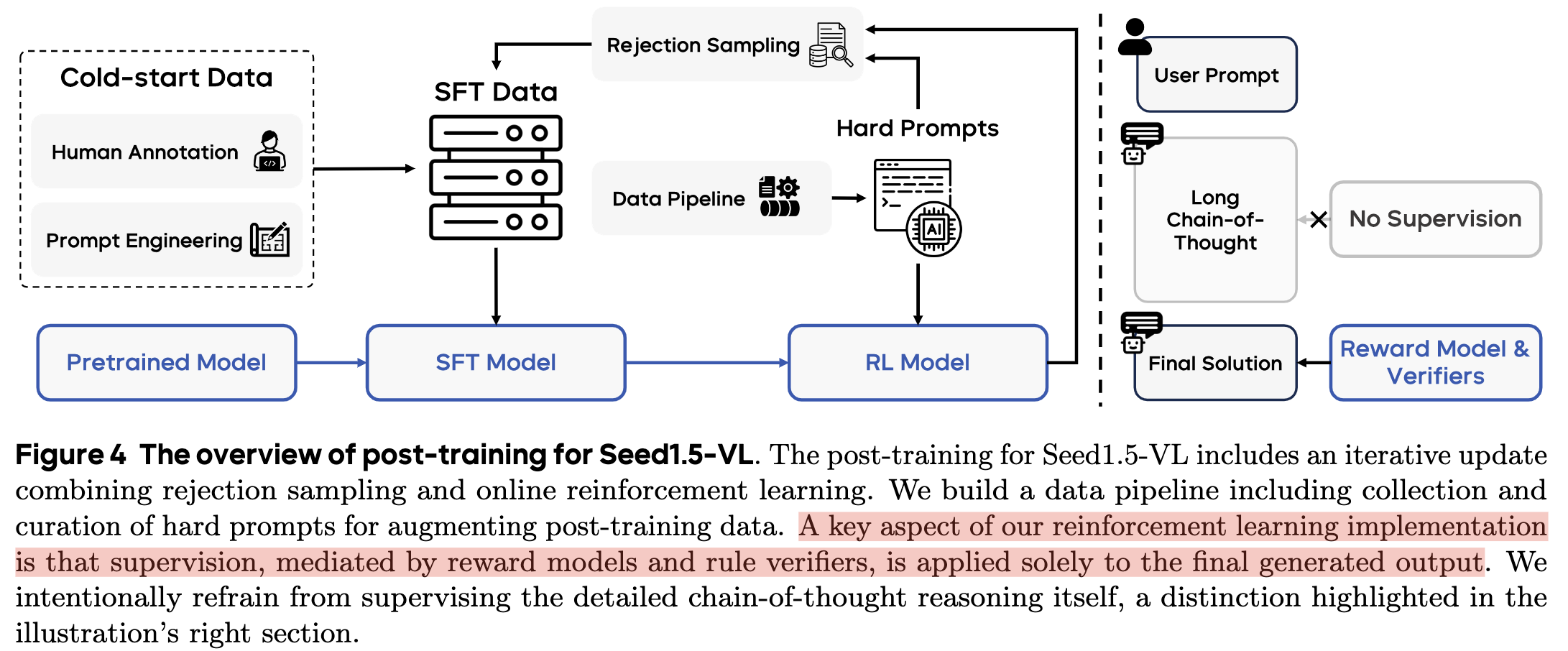
post-traing阶段训练流程如下
详细的论文阅读笔记见我的飞书文档: Seed-Vl系列论文解析